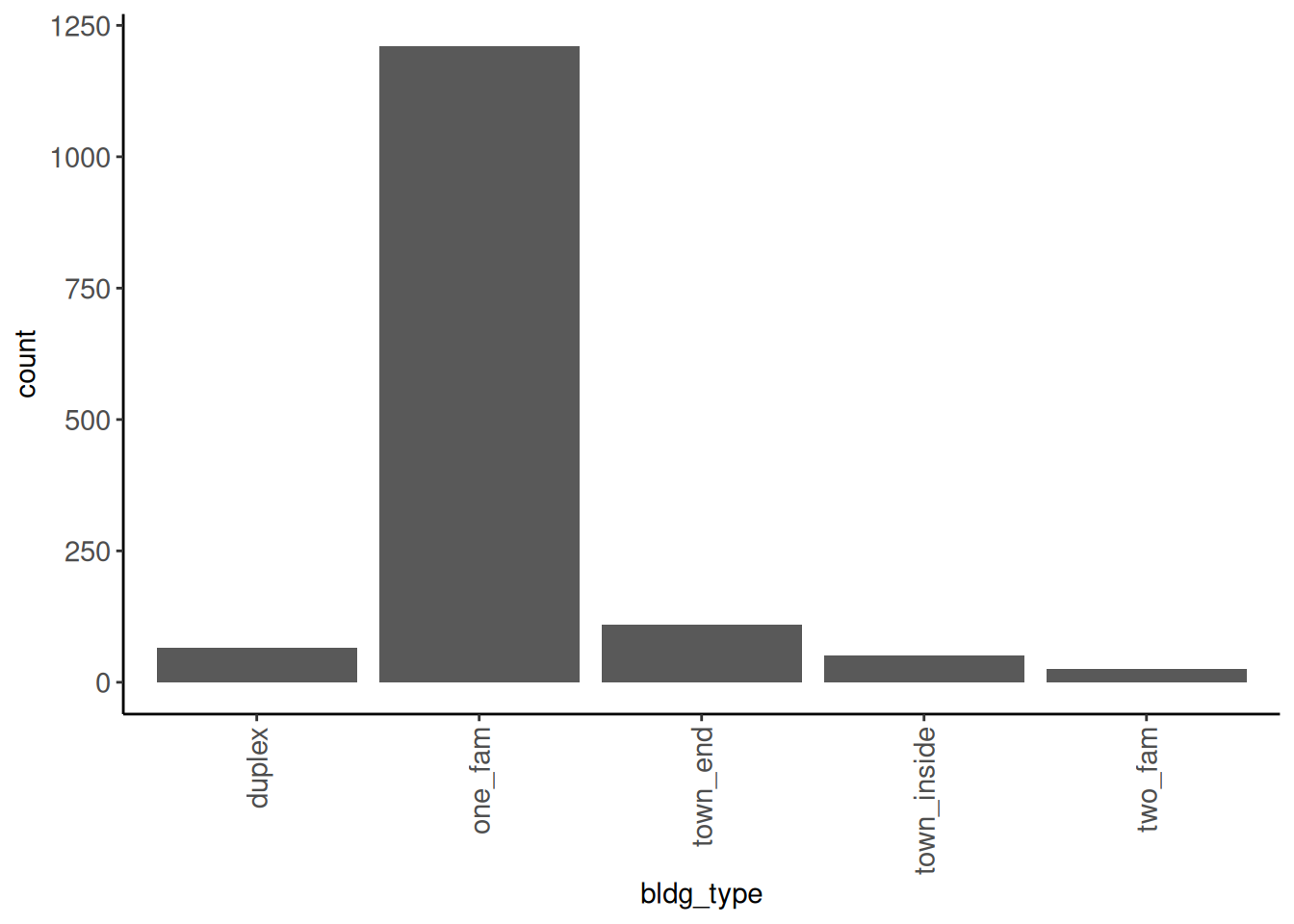
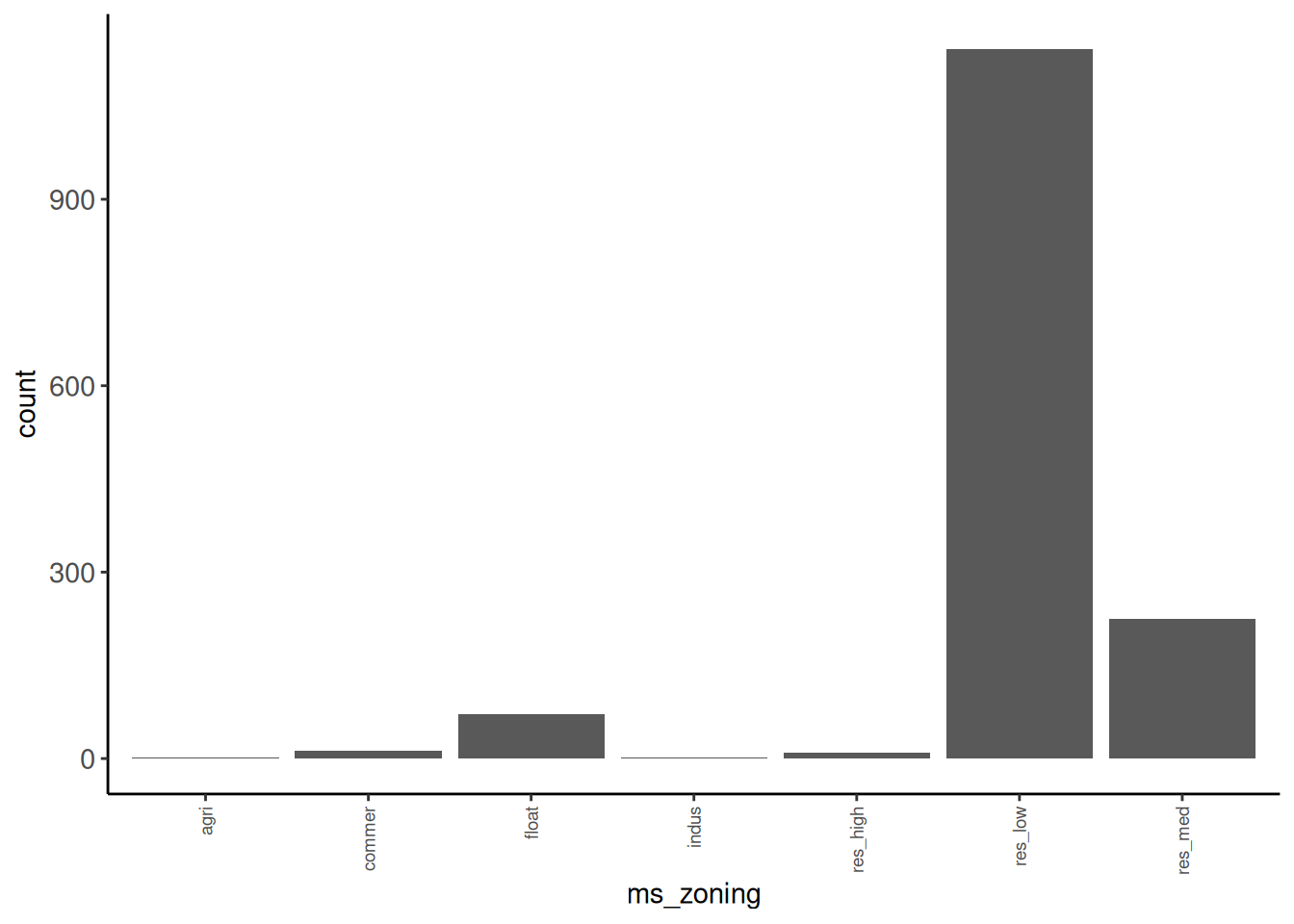
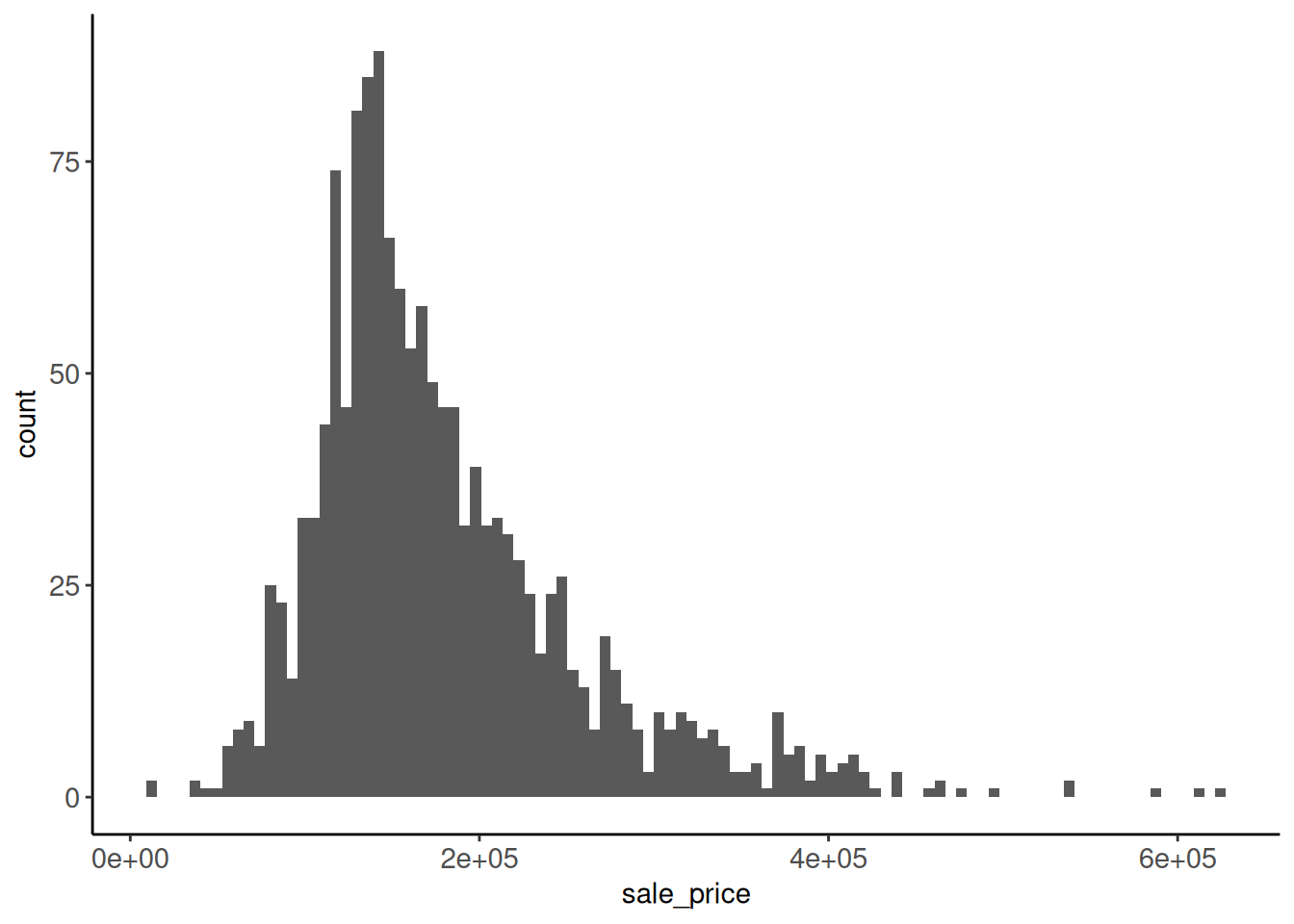
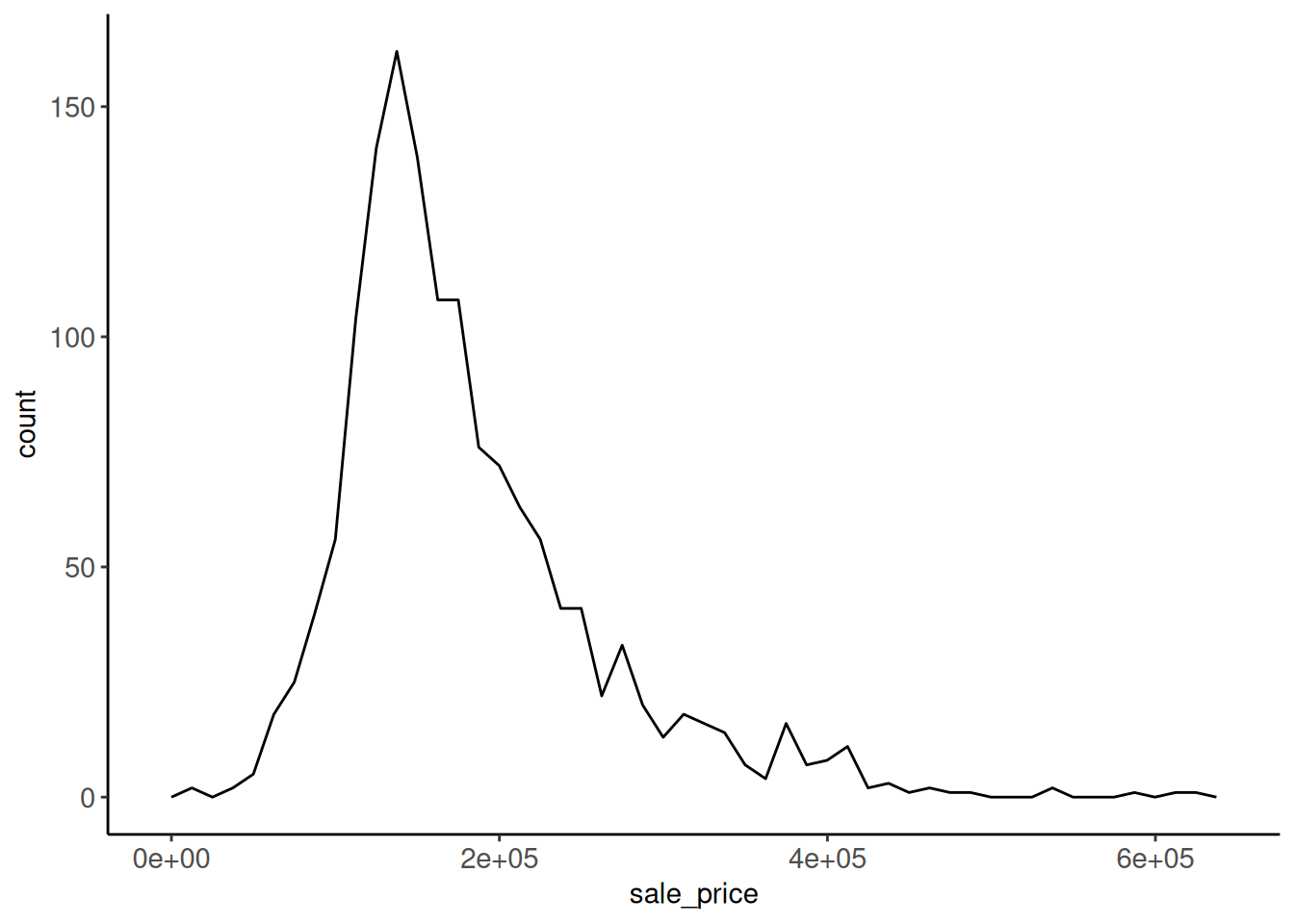
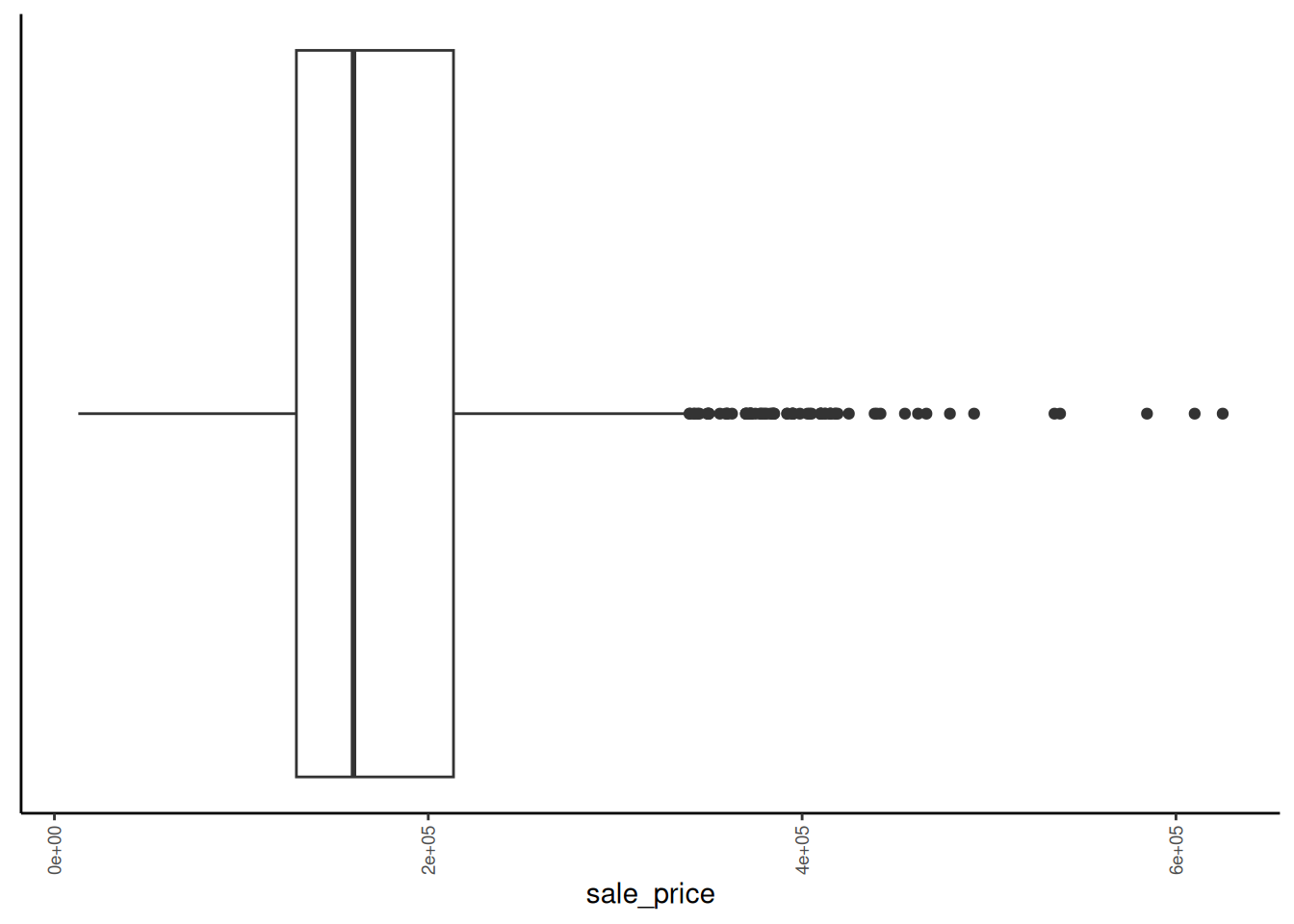
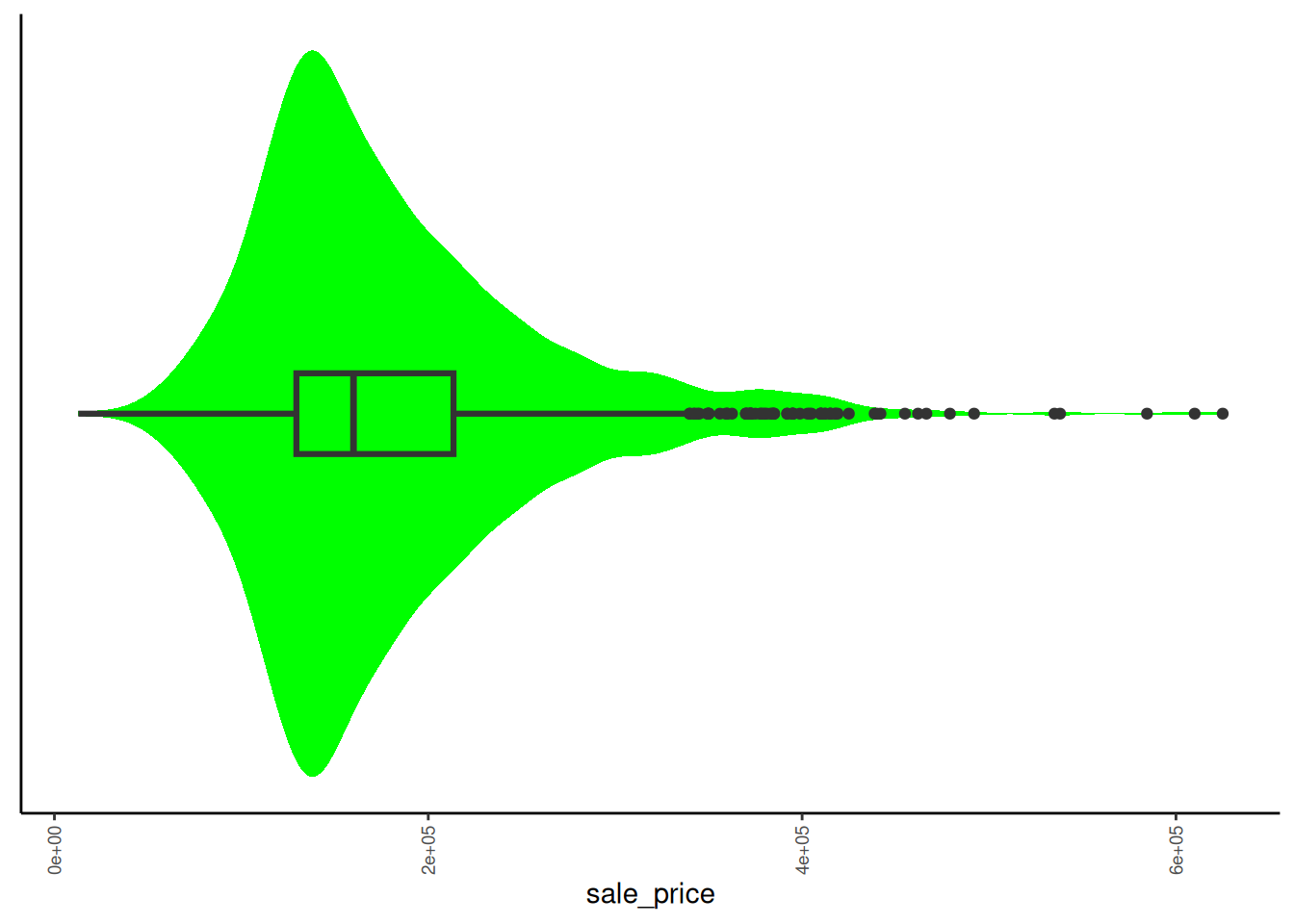
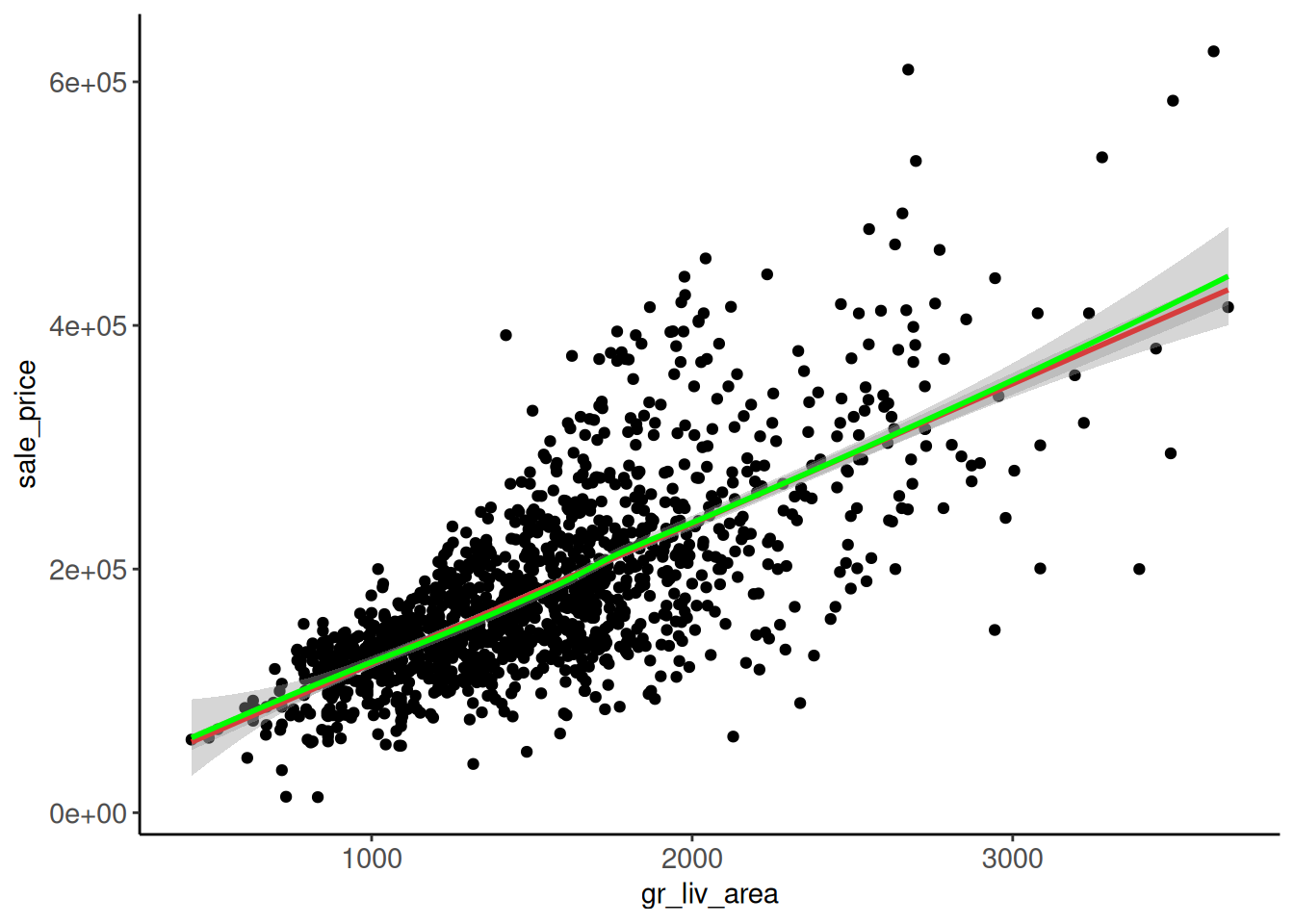
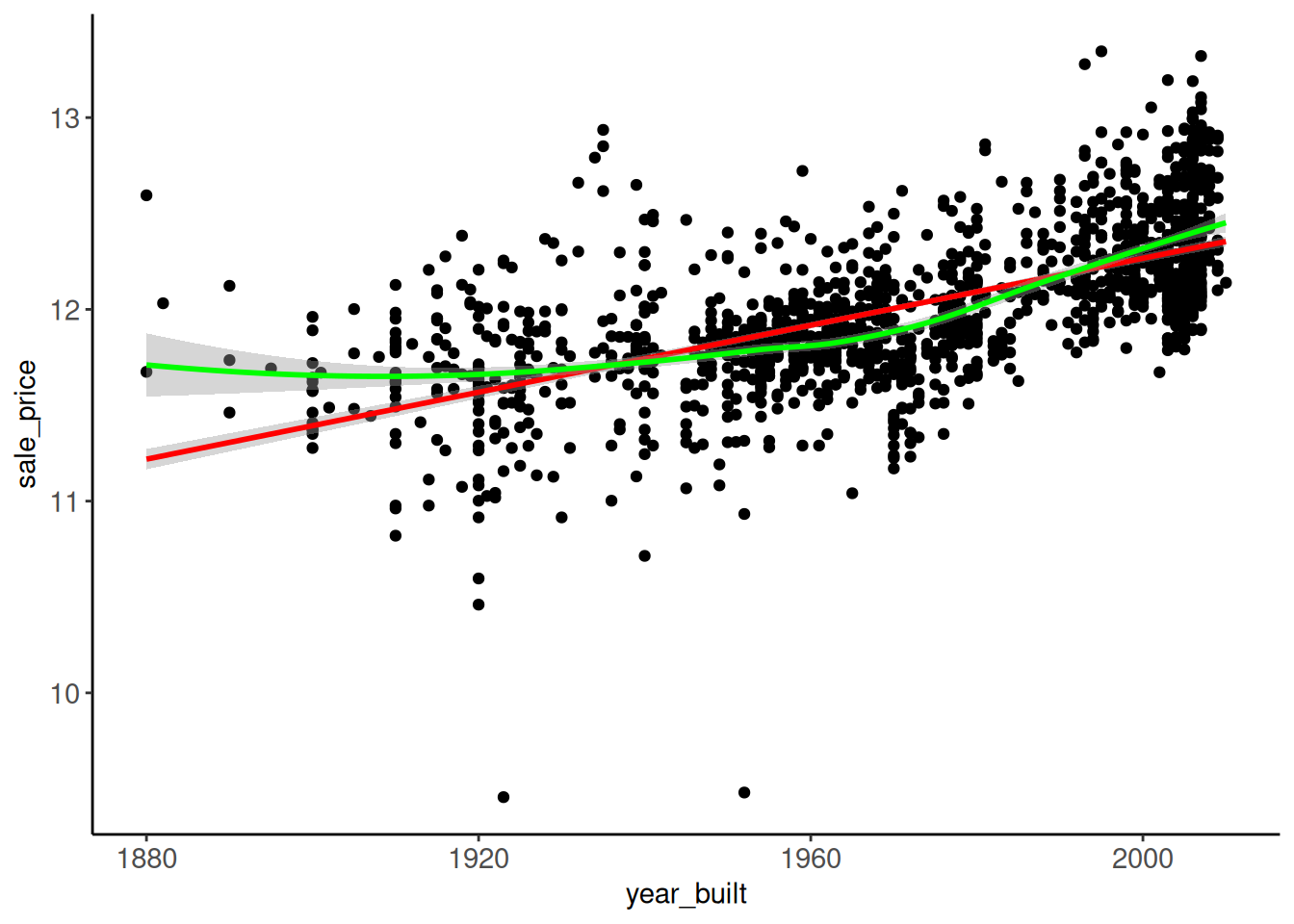
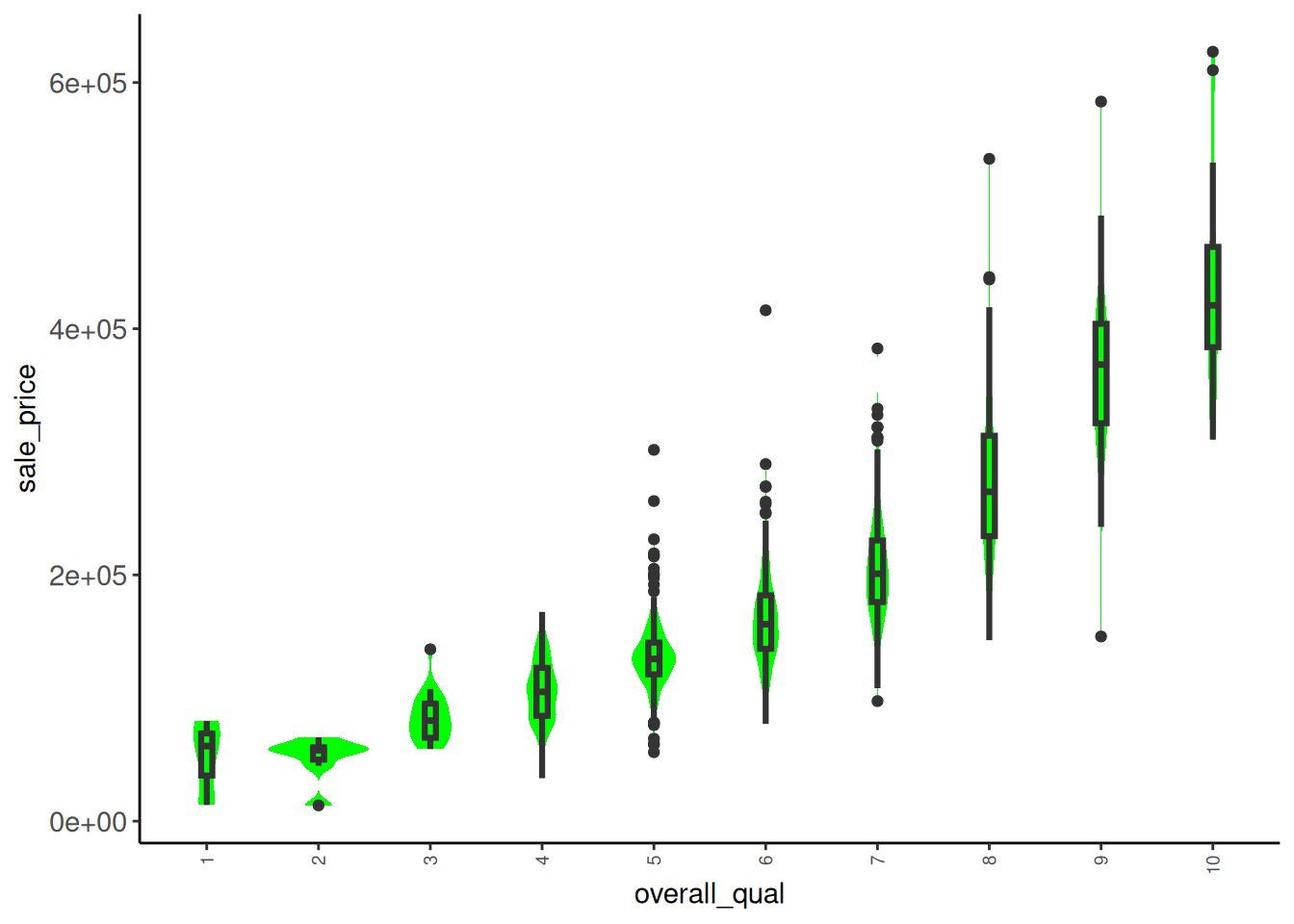
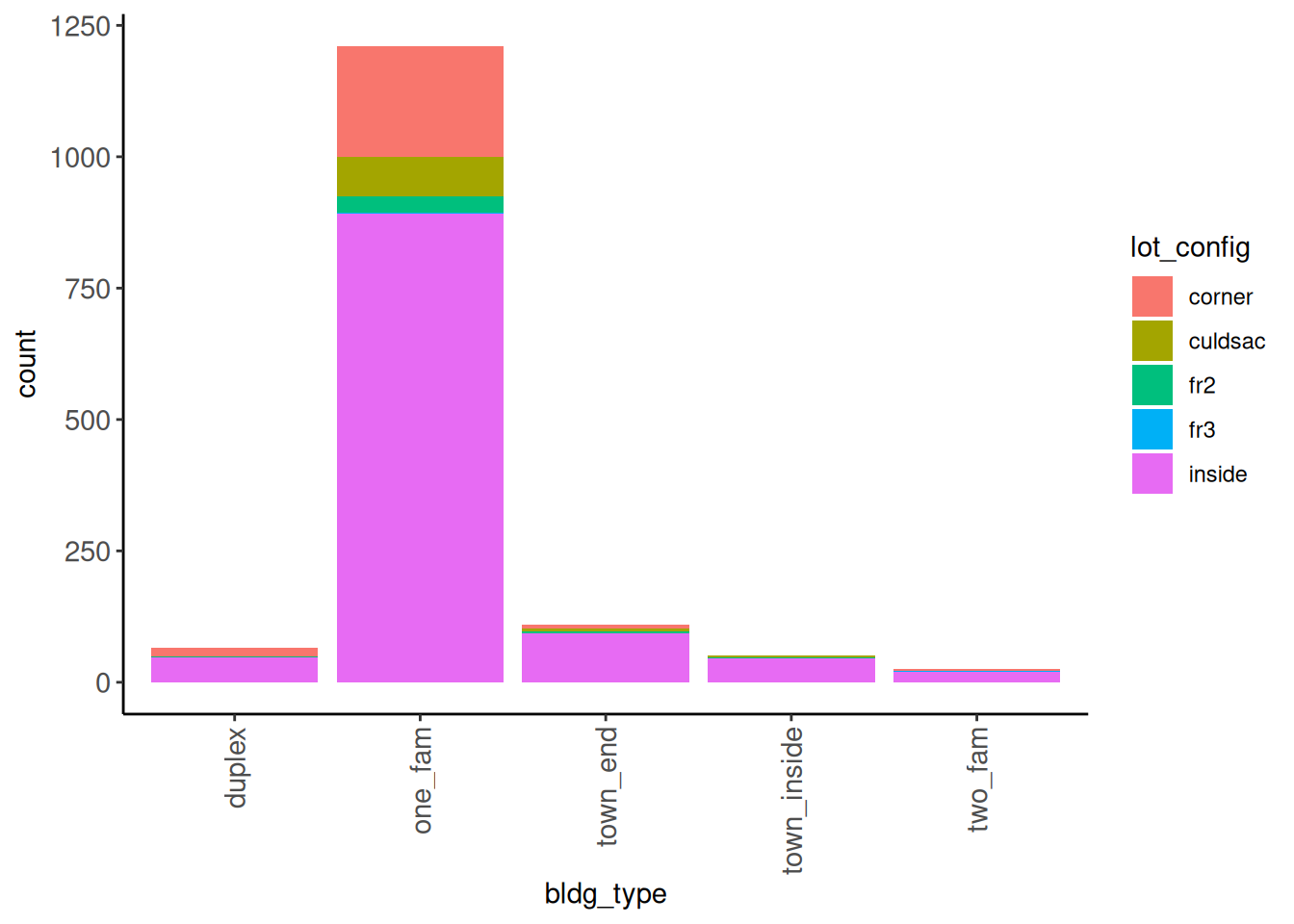
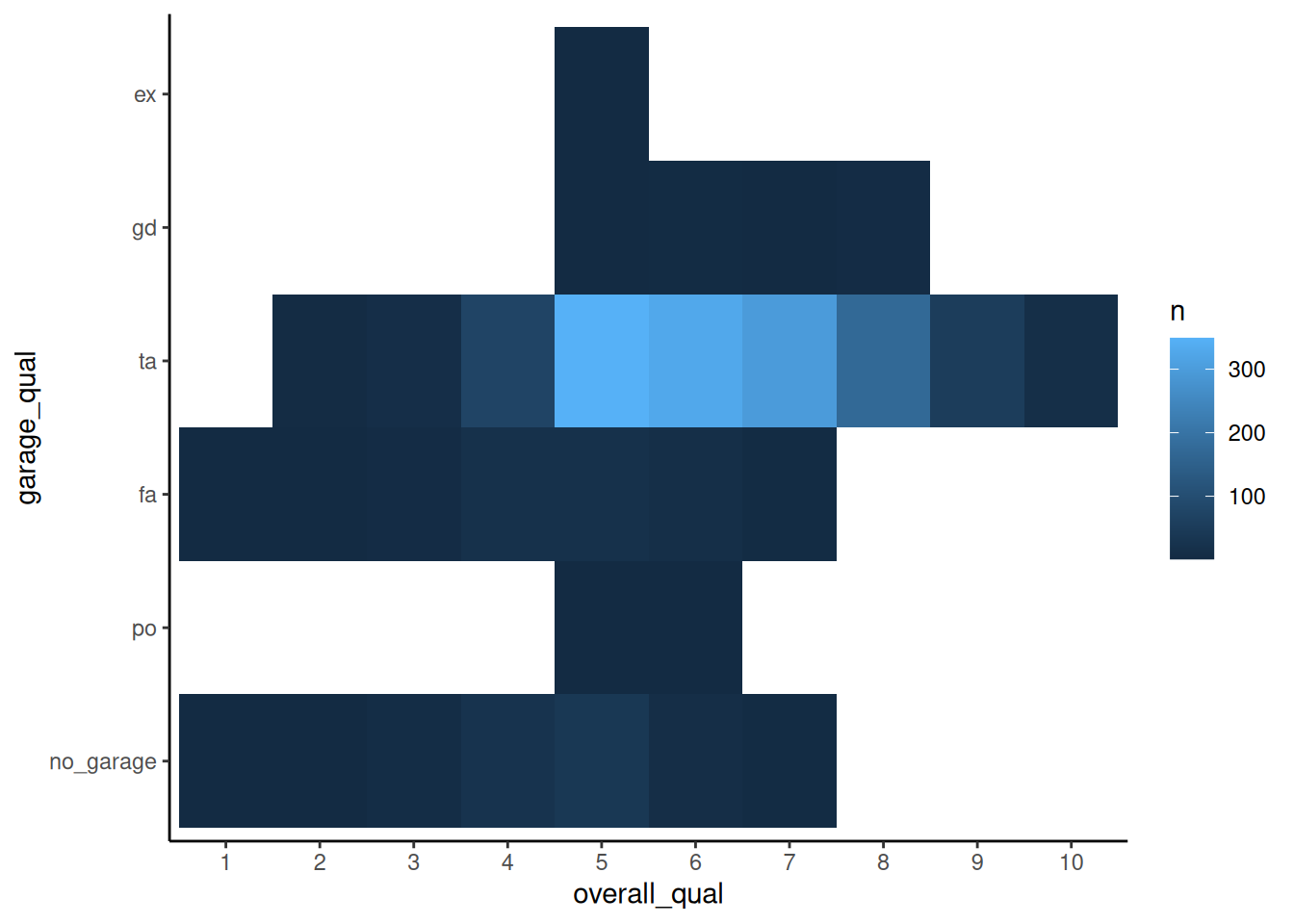
Rows: 1,952
Columns: 81
$ PID <dbl> 526301100, 526350040, 526351010, 527105010, 52712715…
$ `MS SubClass` <dbl> 20, 20, 20, 60, 120, 120, 120, 60, 60, 60, 20, 120, …
$ `MS Zoning` <chr> "RL", "RH", "RL", "RL", "RL", "RL", "RL", "RL", "RL"…
$ `Lot Frontage` <dbl> 141, 80, 81, 74, 41, 43, 39, 60, 75, 63, 85, NA, 47,…
$ `Lot Area` <dbl> 31770, 11622, 14267, 13830, 4920, 5005, 5389, 7500, …
$ Street <chr> "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pav…
$ Alley <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ `Lot Shape` <chr> "IR1", "Reg", "IR1", "IR1", "Reg", "IR1", "IR1", "Re…
$ `Land Contour` <chr> "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "HLS", "Lvl", "Lv…
$ Utilities <chr> "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "A…
$ `Lot Config` <chr> "Corner", "Inside", "Corner", "Inside", "Inside", "I…
$ `Land Slope` <chr> "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gt…
$ Neighborhood <chr> "NAmes", "NAmes", "NAmes", "Gilbert", "StoneBr", "St…
$ `Condition 1` <chr> "Norm", "Feedr", "Norm", "Norm", "Norm", "Norm", "No…
$ `Condition 2` <chr> "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", "Nor…
$ `Bldg Type` <chr> "1Fam", "1Fam", "1Fam", "1Fam", "TwnhsE", "TwnhsE", …
$ `House Style` <chr> "1Story", "1Story", "1Story", "2Story", "1Story", "1…
$ `Overall Qual` <dbl> 6, 5, 6, 5, 8, 8, 8, 7, 6, 6, 7, 8, 8, 8, 9, 4, 6, 6…
$ `Overall Cond` <dbl> 5, 6, 6, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 7, 2, 5, 6, 6…
$ `Year Built` <dbl> 1960, 1961, 1958, 1997, 2001, 1992, 1995, 1999, 1993…
$ `Year Remod/Add` <dbl> 1960, 1961, 1958, 1998, 2001, 1992, 1996, 1999, 1994…
$ `Roof Style` <chr> "Hip", "Gable", "Hip", "Gable", "Gable", "Gable", "G…
$ `Roof Matl` <chr> "CompShg", "CompShg", "CompShg", "CompShg", "CompShg…
$ `Exterior 1st` <chr> "BrkFace", "VinylSd", "Wd Sdng", "VinylSd", "CemntBd…
$ `Exterior 2nd` <chr> "Plywood", "VinylSd", "Wd Sdng", "VinylSd", "CmentBd…
$ `Mas Vnr Type` <chr> "Stone", "None", "BrkFace", "None", "None", "None", …
$ `Mas Vnr Area` <dbl> 112, 0, 108, 0, 0, 0, 0, 0, 0, 0, 0, 0, 603, 0, 350,…
$ `Exter Qual` <chr> "TA", "TA", "TA", "TA", "Gd", "Gd", "Gd", "TA", "TA"…
$ `Exter Cond` <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA"…
$ Foundation <chr> "CBlock", "CBlock", "CBlock", "PConc", "PConc", "PCo…
$ `Bsmt Qual` <chr> "TA", "TA", "TA", "Gd", "Gd", "Gd", "Gd", "TA", "Gd"…
$ `Bsmt Cond` <chr> "Gd", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA"…
$ `Bsmt Exposure` <chr> "Gd", "No", "No", "No", "Mn", "No", "No", "No", "No"…
$ `BsmtFin Type 1` <chr> "BLQ", "Rec", "ALQ", "GLQ", "GLQ", "ALQ", "GLQ", "Un…
$ `BsmtFin SF 1` <dbl> 639, 468, 923, 791, 616, 263, 1180, 0, 0, 0, 637, 36…
$ `BsmtFin Type 2` <chr> "Unf", "LwQ", "Unf", "Unf", "Unf", "Unf", "Unf", "Un…
$ `BsmtFin SF 2` <dbl> 0, 144, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1120, 0, 0, 0, 0,…
$ `Bsmt Unf SF` <dbl> 441, 270, 406, 137, 722, 1017, 415, 994, 763, 789, 6…
$ `Total Bsmt SF` <dbl> 1080, 882, 1329, 928, 1338, 1280, 1595, 994, 763, 78…
$ Heating <chr> "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "Gas…
$ `Heating QC` <chr> "Fa", "TA", "TA", "Gd", "Ex", "Ex", "Ex", "Gd", "Gd"…
$ `Central Air` <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y…
$ Electrical <chr> "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr"…
$ `1st Flr SF` <dbl> 1656, 896, 1329, 928, 1338, 1280, 1616, 1028, 763, 7…
$ `2nd Flr SF` <dbl> 0, 0, 0, 701, 0, 0, 0, 776, 892, 676, 0, 0, 1589, 67…
$ `Low Qual Fin SF` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ `Gr Liv Area` <dbl> 1656, 896, 1329, 1629, 1338, 1280, 1616, 1804, 1655,…
$ `Bsmt Full Bath` <dbl> 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0…
$ `Bsmt Half Bath` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ `Full Bath` <dbl> 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 3, 2, 1, 1, 2, 2…
$ `Half Bath` <dbl> 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0…
$ `Bedroom AbvGr` <dbl> 3, 2, 3, 3, 2, 2, 2, 3, 3, 3, 2, 1, 4, 4, 1, 2, 3, 3…
$ `Kitchen AbvGr` <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ `Kitchen Qual` <chr> "TA", "TA", "Gd", "TA", "Gd", "Gd", "Gd", "Gd", "TA"…
$ `TotRms AbvGrd` <dbl> 7, 5, 6, 6, 6, 5, 5, 7, 7, 7, 5, 4, 12, 8, 8, 4, 7, …
$ Functional <chr> "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Ty…
$ Fireplaces <dbl> 2, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 2, 1…
$ `Fireplace Qu` <chr> "Gd", NA, NA, "TA", NA, NA, "TA", "TA", "TA", "Gd", …
$ `Garage Type` <chr> "Attchd", "Attchd", "Attchd", "Attchd", "Attchd", "A…
$ `Garage Yr Blt` <dbl> 1960, 1961, 1958, 1997, 2001, 1992, 1995, 1999, 1993…
$ `Garage Finish` <chr> "Fin", "Unf", "Unf", "Fin", "Fin", "RFn", "RFn", "Fi…
$ `Garage Cars` <dbl> 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 3, 2, 2, 2…
$ `Garage Area` <dbl> 528, 730, 312, 482, 582, 506, 608, 442, 440, 393, 50…
$ `Garage Qual` <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA"…
$ `Garage Cond` <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA"…
$ `Paved Drive` <chr> "P", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y…
$ `Wood Deck SF` <dbl> 210, 140, 393, 212, 0, 0, 237, 140, 157, 0, 192, 0, …
$ `Open Porch SF` <dbl> 62, 0, 36, 34, 0, 82, 152, 60, 84, 75, 0, 54, 36, 12…
$ `Enclosed Porch` <dbl> 0, 0, 0, 0, 170, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ `3Ssn Porch` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ `Screen Porch` <dbl> 0, 120, 0, 0, 0, 144, 0, 0, 0, 0, 0, 140, 210, 0, 0,…
$ `Pool Area` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ `Pool QC` <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ Fence <chr> NA, "MnPrv", NA, "MnPrv", NA, NA, NA, NA, NA, NA, NA…
$ `Misc Feature` <chr> NA, NA, "Gar2", NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ `Misc Val` <dbl> 0, 0, 12500, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ `Mo Sold` <dbl> 5, 6, 6, 3, 4, 1, 3, 6, 4, 5, 2, 6, 6, 6, 6, 6, 2, 1…
$ `Yr Sold` <dbl> 2010, 2010, 2010, 2010, 2010, 2010, 2010, 2010, 2010…
$ `Sale Type` <chr> "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD"…
$ `Sale Condition` <chr> "Normal", "Normal", "Normal", "Normal", "Normal", "N…
$ SalePrice <dbl> 215000, 105000, 172000, 189900, 213500, 191500, 2365…