9Advanced Models: Decision Trees, Bagging Trees, and Random Forest
9.1 Learning Objectives
Decision trees
Bagged trees
How to bag models and the benefits
Random Forest
How Random Forest extends bagged trees
Feature interpretation with decision tree plots
9.2 Decision Trees
Tree-based statistical algorithms:
Are a class of flexible, nonparametric algorithms
Work by partitioning the feature space into a number of smaller non-overlapping regions with similar responses by using a set of splitting rules
Make predictions by assigning a single prediction to each of these regions
Can produce simple rules that are easy to interpret and visualize with tree diagrams
Typically lack in predictive performance compared to other common algorithms
Serve as base learners for more powerful ensemble approaches
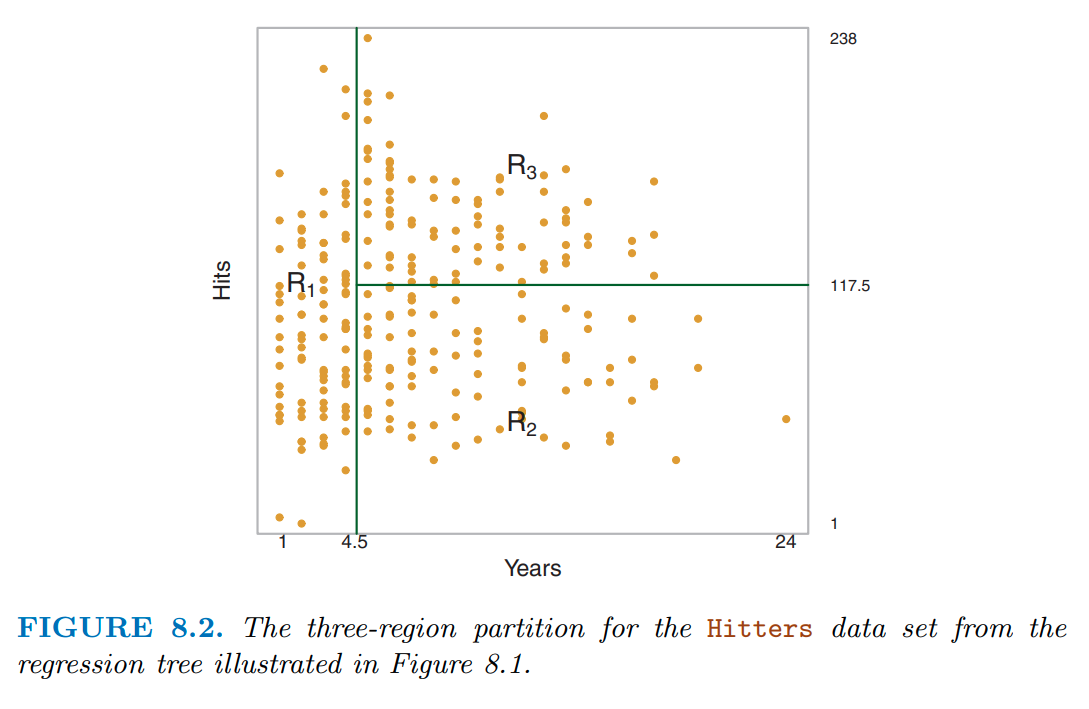
In figure 8.1 from James et al. (2023), they display a simple tree to predict log(salary) using years in the major league and hits from the previous year
This tree only has a depth of two (there are only two levels of splits)
years < 4.5
hits < 117.5
This results in three regions
years < 4.5
years >= 4.5 & hits < 117.5
years >= 4.5 & hits >= 117.5
A single value for salary is predicted for each of these three regions
Decision trees are very interpretable. How we make decisions?
You can see these regions more clearly in the two-dimensional feature space displayed in figure 8.2
Notice how even with a limited tree depth of 2, we can already get a complex partitioning of the feature space.
Decision trees can encode complex decision boundaries (and even more complex than this as tree depth increases)
There are many methodologies for constructing decision trees but the most well-known is the classification and regression tree (CART) algorithm proposed in Breiman (1984)
This algorithm is implemented in the rpartpackage and this is the engine we will use in tidymodels for decision trees (and bagged trees - a more advance ensemble method)
The decision tree partitions the training data into homogeneous subgroups (i.e., groups with similar response values)
These subgroups are called nodes
The nodes are formed recursively using binary partitions by asking simple yes-or-no questions about each feature (e.g., are years in major league < 4.5?)
This is done a number of times until a suitable stopping criteria is satisfied, e.g.,
a maximum depth of the tree is reached
minimum number of remaining observations is available in a node
After all the partitioning has been done, the model predicts a single value for each region
mean response among all observations in the region for regression problems
majority vote among all observations in the region for classification problems
probabilities (for classification) can be obtained using the proportion of each class within the region
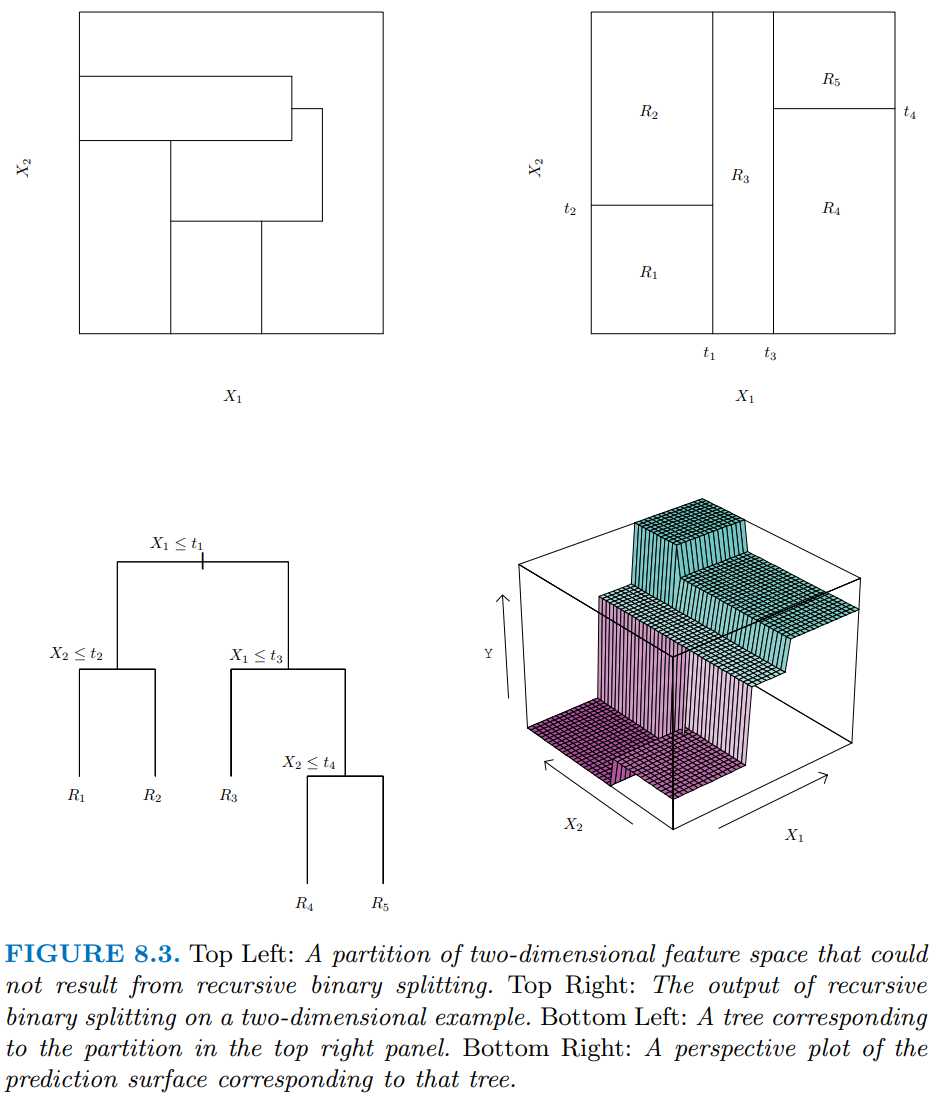
The bottom left panel in Figure 8.3 shows a slightly more complicated tree with depth = 3 for two arbitrary predictors (x1 and x2)
The right column shows a representation of the regions formed by this tree (top) and a 3D representation that includes predictions for y (bottom)
The top left panel displays a set of regions that is NOT possible using binary recursive splitting. This makes the point that there are some patterns in the data that cannot be accommodated well by decision trees
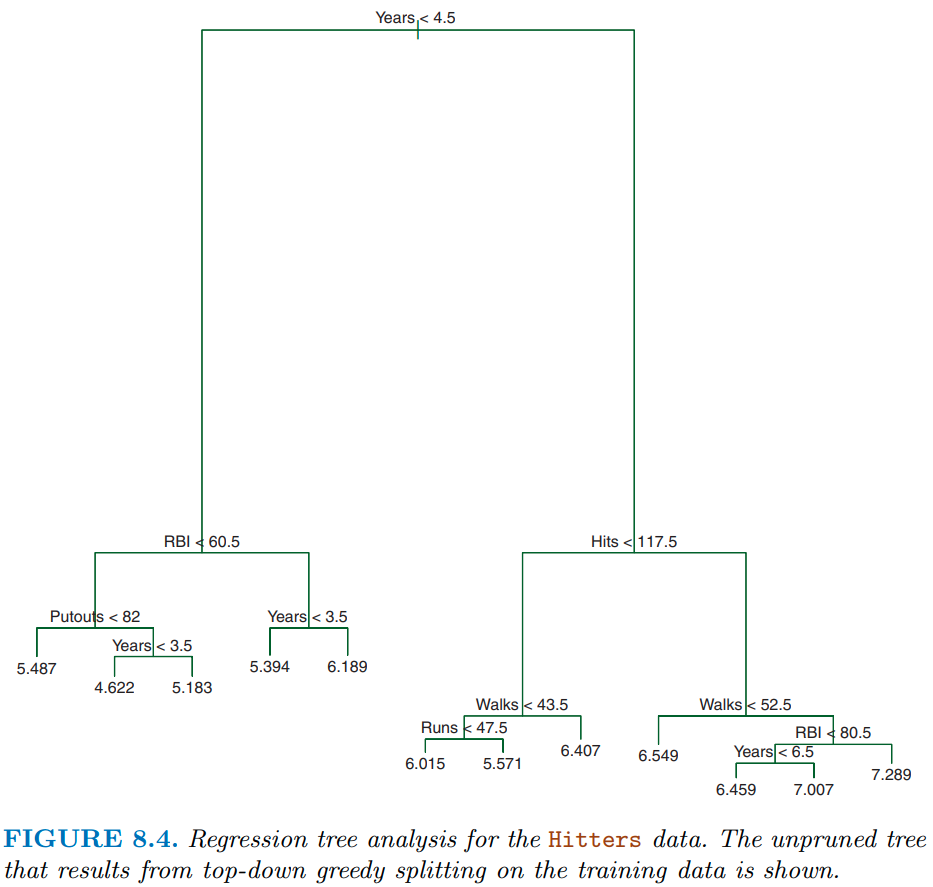
Figure 8.4 shows a slightly more complicated decision tree for the hitters dataset with tree depth = 4. With respect to terminology:
As noted earlier, each of the subgroups are called nodes
The first “subgroup”” at the top of the tree is called the root node. This node contains all of the training data.
The final subgroups at the bottom of the tree are called the terminal nodes or leaves (the “tree” is upside down)
Every subgroup in between is referred to as an internal node.
The connections between nodes are called branches
This tree also highlights another key point. The same features can be used for splitting repeatedly throughout the tree.
CART uses binary recursive partitioning
Recursive simply means that each split (or rule) depends on the the splits above it:
The algorithm first identifies the “best” feature to partition the observations in the root node into one of two new regions (i.e., new nodes that will be on the left and right branches leading from the root node.)
For regression problems, the “best” feature (and the rule using that feature) is the feature that maximizes the reduction in SSE
For classification problems, the split is selected to maximize the reduction in cross-entropy or the Gini index. These are measures of impurity (and we want to get homogeneous nodes so we minimize them)
The splitting process is then repeated on each of the two new nodes (hence the name binary recursive partitioning).
This process is continued until a suitable stopping criterion is reached.
The final depth of the tree is what affects the bias/variance trade-off for this algorithm
Deep trees (with smaller and smaller sized nodes) will have lower and lower bias but can become overfit to the training data
Shallow trees may be overly biased (underfit)
There are two primary approaches to achieve the optimal balance in the bias-variance trade-off
Early stopping
Pruning
With early stopping:
We explicitly stop the growth of the tree early based on a stopping rule. The two most common are:
A maximum tree depth is reached
The node has too few cases to be considered for further splits
These two stopping criteria can be implemented independently of each other but they do interact
They should ideally be tuned via the cross-validation approaches we have learned
With pruning, we let the tree grow large (max depth = 30 on 32-bit machines) and then prune it back to an optimal size:
To do this, we apply a penalty (\(\lambda\) * # of terminal nodes) to the cost function/impurity index (analogous to the L1/LASSO penalty). This penalty is also referred to as the cost complexity parameter
Big values for cost complexity will result in less complex trees. Small values will result in deeper, more complex trees
Cost complexity can be tuned by our standard cross-validation approaches by itself or in combination with the previous two hyper parameters
Feature engineering for decision trees can be simpler than with other algorithms because there are very few pre-processing requirements:
Monotonic transformations (e.g., power transformations) are not required to meet algorithm assumptions (in contrast to many parametric models). These transformations only shift the location of the optimal split points.
Outliers typically do not bias the results as much since the binary partitioning simply looks for a single location to make a split within the distribution of each feature.
The algorithm will handle non-linear effects of features and interactions natively
Categorical predictors do not need pre-processing to convert to numeric (e.g., dummy coding).
For unordered categorical features with more than two levels, the classes are ordered based on the outcome
For regression problems, the mean of the response is used
For classification problems, the proportion of the positive outcome class is used.
This means that aggregating response levels is not necessary
Most decision tree implementations (including the rpart engine) can easily handle missing values in the features and do not require imputation. In rpart, this is handled by using surrogate splits.
It is important to note that feature engineering (e.g., alternative strategies for missing data, categorical level aggregation) may still improve performance, but this algorithm does not have the same pre-processing requirements we have seen previously and will work fairly well “out of the box”.
9.3 Decision Trees in Ames
Let’s see this algorithm in action
We will explore the decision tree algorithm (and ensemble approaches using it) with the Ames Housing Prices database
Parallel processing is VERY useful for ensemble approaches because they can be computationally costly
Will handle non-linear relationships and interactions natively
Dummy coding not needed (and generally not recommended) for factors
Not even very important to consider frequency of response categories
Not even necessary to convert character to factor (but I do to make it easy to do further feature engineering if desired)
Be careful with categorical variables which are coded with numbers
They will be coded as numeric by R and treated as numeric by R
If they are ordered (overall_qual), this a priori order would be respected by rpart so no worries
If they are unordered, this will force an order on the levels rather than allowing rpart to determine an order based on the outcome in your training data.
Notice the missing data for features (rpart will handle it with surrogates)
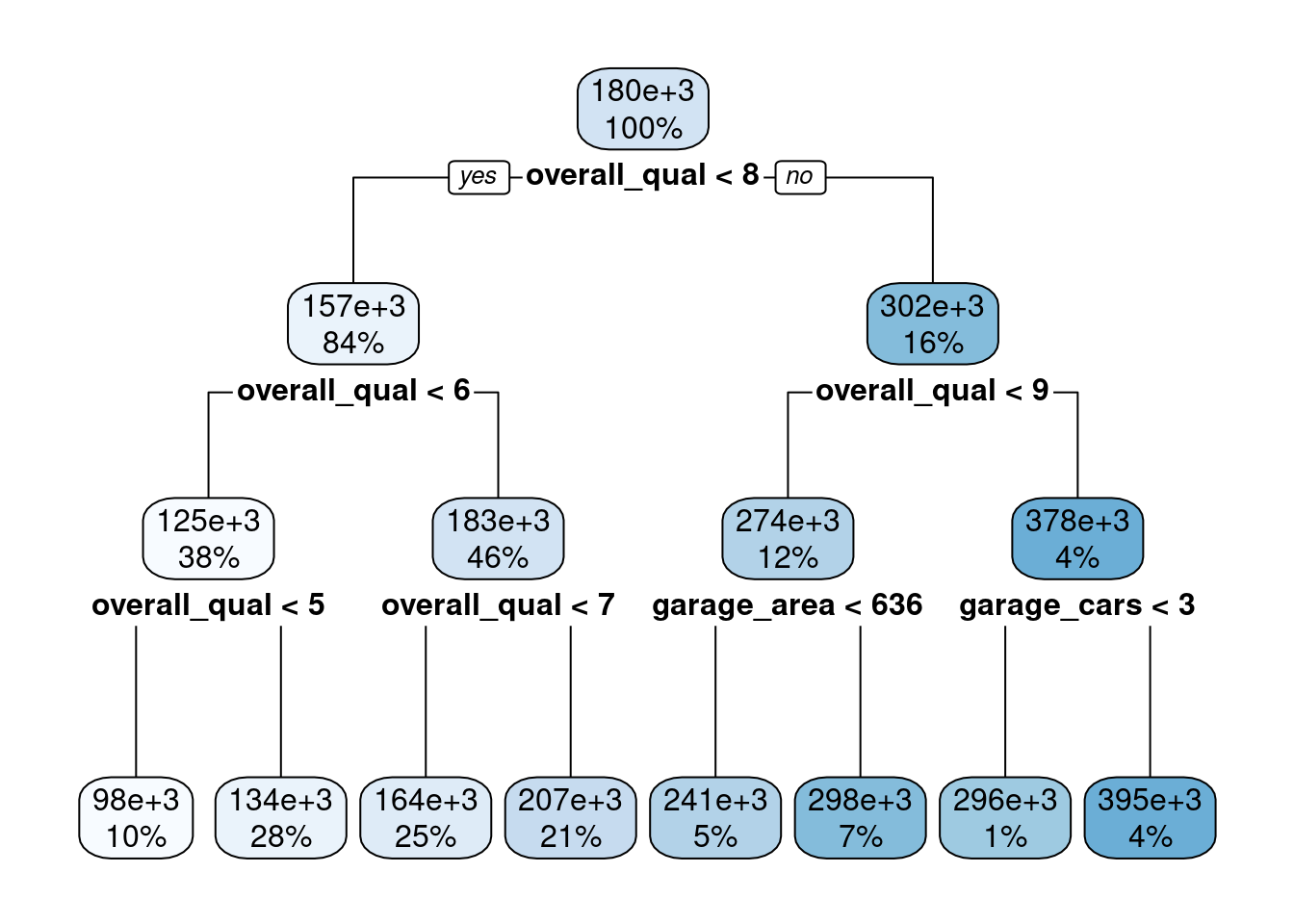
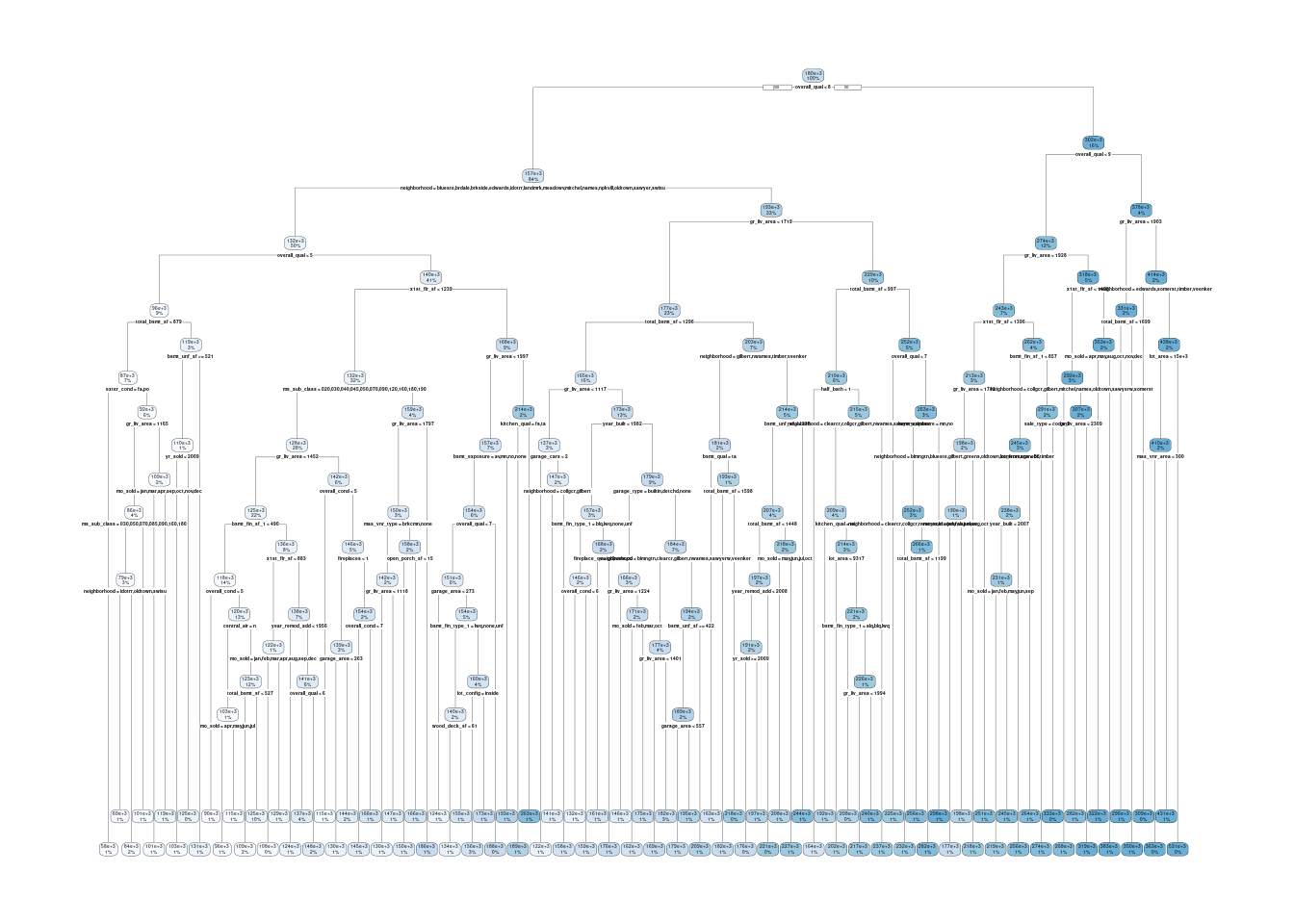
Let’s plot the decision tree using rpart.plot for a package with the same name. No need to load the full package
Easy to understand how the model makes predictions
Code
fit_tree_ex1$fit |> rpart.plot::rpart.plot()
ImportantQuestion: How can we determine how well this model predicts sale_price?
We need held out data. We could do a validation split, k-fold, or bootstraps. K-fold may be preferred b/c it provides a less biased estimate of model performance.
I will use bootstrap cross-validation instead because I will later use these same splits to also choose among hyperparameter values.]
Using only 10 bootstraps to save time. Use more in your work!
Can use autoplot() to view performance by hyperparameter values
Code
# autoplot(fits_tree)
The best values for some of the hyperparameters (tree depth and min n) are at their edges so we might consider extending their range and training again. I will skip this here to save time.
This model as good as our other models in unit 3 (see OOB cross-validated error above). It was easy to fit with all the predictors. It might get even a little better for we further tuned the hyperparameters. However, we can still do better with a more advanced algorithm based on decision trees.
Code
show_best(fits_tree)
Warning in show_best(fits_tree): No value of `metric` was given; "rmse" will be
used.
# A tibble: 5 × 9
cost_complexity tree_depth min_n .metric .estimator mean n std_err
<dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl>
1 0.0001 10 27 rmse standard 36465. 10 700.
2 0.0000000001 10 27 rmse standard 36472. 10 700.
3 0.0000001 10 27 rmse standard 36472. 10 700.
4 0.0001 15 27 rmse standard 36484. 10 699.
5 0.0000000001 15 27 rmse standard 36496. 10 701.
.config
<chr>
1 Preprocessor1_Model43
2 Preprocessor1_Model41
3 Preprocessor1_Model42
4 Preprocessor1_Model47
5 Preprocessor1_Model45
Let’s still fit this tree to all the training data and understand it a bit better
Code
fit_tree <-decision_tree(cost_complexity =select_best(fits_tree)$cost_complexity,tree_depth =select_best(fits_tree)$tree_depth,min_n =select_best(fits_tree)$min_n) |>set_engine("rpart", model =TRUE) |>set_mode("regression") |>fit(sale_price ~ ., data = feat_trn)
Warning in select_best(fits_tree): No value of `metric` was given; "rmse" will be used.
No value of `metric` was given; "rmse" will be used.
No value of `metric` was given; "rmse" will be used.
Still interpretable but need bigger, higher res plot
Code
fit_tree$fit |> rpart.plot::rpart.plot()
Warning: labs do not fit even at cex 0.15, there may be some overplotting
Even though decision trees themselves are relatively poor at prediction, these ideas will be key when we consider more advanced ensemble approaches
Ensemble approaches aggregate multiple models to improve prediction. Our first ensemble approach is bagging.
Combining (or ensembling) them into an aggregated prediction
You can begin to learn more about bagging in the original paper that proposed the technique
The specific steps are:
B bootstraps of the original training data are created [NOTE: This is a new use for bootstrapping! More on that in a moment]
The model configuration (either regression or classification algorithm with a specific set of features and hyperparameters) is fit to each bootstrap sample
These individual fitted models are called the base learners
Final predictions are made by aggregating the predictions across all of the individual base learners
For regression, this can be the average of base learner predictions
For classification, it can be either the average of estimated class probabilities or majority class vote across individual base learners
Bagging effectively reduces the variance of an individual base learner
However, bagging does not always improve on an individual base learner
Bagging works especially well for flexible, high variance base learners (based on statistical algorithms or other characteristics of the problem)
These base learners can become overfit to their training data
Therefore base learners will produce different predictions across each bootstrap sample of the training data
The aggregate predictions across base learners will be lower variance
With respect to statistical algorithms that you know, decision trees are high variance (KNN also)
In contrast, bagging a linear model (with low P to N ratio) would likely not improve much upon the base learners’ performance
Bagging takes advantage of the “wisdom of the crowd” effect (Surowiecki, 2005)
Aggregation of information across large diverse groups often produces decisions that are better than any single member of the group
Regis Philbin once stated that the Ask the Audience lifeline on Who Wants to be a Millionaire is right 95% of the time
With more diverse group members and perspectives (i.e., high variance learners), we get better aggregated predictions
With decision trees, optimal performance is often found by bagging 50-500 base learner trees
Data sets that have a few strong features typically require fewer trees
Data sets with lots of noise or multiple strong features may need more
Using too many trees will NOT lead to overfitting, just no further benefit in variance reduction
However, too many trees will increase computational costs (particularly if you are also using “an outer loop” of resampling to select among configurations or to evaluate the model)
Bagging uses bootstrap resampling for yet another goal. We can use bootstrapping
For cross-validation to assess performance model configuration(s)
Select among model model configurations
Evaluate a final model configuration (if we don’t have independent test set)
For estimating standard errors and confidence intervals of statistics (no longer part of this course - see Appendix)
And now for building multiple base learners whose aggregate predictions are lower variance than any of the individual base learners
When bagging, we can (and typically will):
Use an “outer loop” of bootstrap resampling to select among model configurations
While using an “inner loop” of bootstrapping to fit multiple base learners for any specific configuration
This inner loop is often opaque to users (more on this in a moment), happening under the hood in the algorithm (e.g., Random Forest) or the implementation of the code (bagged_tree())
9.5 Bagging Trees in Ames
We will now use bag_tree() rather than decision_tree() from the baguette package. Not part of minimal tidymodels libraries so we will need to load this package
Code
library(baguette)
We can still tune the same hyperparameters. We are now just creating many rpart decision trees and aggregating their predictions. We will START with the recommended values by tidymodels
We can use the same recipe
We will use the same splits to tune hyperparameters
Now we need times = 20 to fit 20 models (inner loop of bootstrapping) to each of the 10 bootstraps (outer loop; set earlier) of the training data.
Keeping this low to reduce computational costs.
You will likely want more bootstrapped models to reduce final model variance and more boostraps resamples to get a lower variance performance estimate to select best hyperparameters
This looks better. And look at that BIG improvement in OOB cross-validated RMSE
Code
show_best(fits_bagged_2)
Warning in show_best(fits_bagged_2): No value of `metric` was given; "rmse"
will be used.
# A tibble: 5 × 9
cost_complexity tree_depth min_n .metric .estimator mean n std_err
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl>
1 0.0000000001 10 2 rmse standard 27584. 10 628.
2 0.0001 30 2 rmse standard 27616. 10 577.
3 0.0001 10 2 rmse standard 27620. 10 684.
4 0.0001 15 14 rmse standard 27777. 10 575.
5 0.0000000001 30 2 rmse standard 27814. 10 662.
.config
<chr>
1 Preprocessor1_Model01
2 Preprocessor1_Model45
3 Preprocessor1_Model33
4 Preprocessor1_Model38
5 Preprocessor1_Model13
BUT, we can do better still…..
9.6 Random Forest
Random forests are a modification of bagged decision trees that build a large collection of de-correlated trees to further improve predictive performance.
They are a very popular “out-of-the-box” or “off-the-shelf” statistical algorithm that predicts well
Many modern implementations of random forests exist; however, Breiman’s algorithm (Breiman 2001) has largely become the standard procedure.
We will use the ranger engine implementation of this algorithm
Random forests build on decision trees (its base learners) and bagging to reduce final model variance.
Simply bagging trees is not optimal to reduce final model variance
The trees in bagging are not completely independent of each other since all the original features are considered at every split of every tree.
Trees from different bootstrap samples typically have similar structure to each other (especially at the top of the tree) due to any underlying strong relationships
The trees are correlated (not as diverse a set of base learners)
Random forests help to reduce tree correlation by injecting more randomness into the tree-growing process
More specifically, while growing a decision tree during the bagging process, random forests perform split-variable randomization where each time a split is to be performed, the search for the best split variable is limited to a random subset of mtry of the original p features.
Because the algorithm randomly selects a bootstrap sample to train on and a random sample of features to use at each split, a more diverse set of trees is produced which tends to lessen tree correlation beyond bagged trees and often dramatically increases predictive power.
There are three primary hyper-parameters to consider tuning in random forests within tidymodels
mtry
trees
min_n
mtry
The number of features to randomly select for splitting on each split
Selection of value for mtry balances low tree correlation with reasonable predictive strength
Good starting values for mtry are \(\frac{p}{3}\) for regression and \(\sqrt{p}\) for classification
When there are fewer relevant features (e.g., noisy data) a higher value may be needed to make it more likely to select those features with the strongest signal.
When there are many relevant features, a lower value might perform better
Default in ranger is \(\sqrt{p}\)
trees
The number of bootstrap resamples of the training data to fit decision tree base learners
The number of trees needs to be sufficiently large to stabilize the error rate.
A good rule of thumb is to start with 10 times the number of features
You may need to adjust based on values for mtry and min_n
More trees provide more robust and stable error estimates and variable importance measures
More trees == more computational cost
Default in ranger is 500
min_n
Minimum number of observations in a new node rather than min to split
Note that this is different than its definition for decision trees and bagged trees
You can consider the defaults (above) as a starting point
If your data has many noisy predictors and higher mtry values are performing best, then performance may improve by increasing node size (i.e., decreasing tree depth and complexity).
If computation time is a concern then you can often decrease run time substantially by increasing the node size and have only marginal impacts to your error estimate
Default in ranger is 1 for classification and 5 for regression
9.6.1 Random Forest in Ames
Let’s see how de-correlated the base learner trees improves their aggregate performance
We will need a new recipe for Random Forest
Random Forest works well out of the box with little feature engineering
It is still aggregating decision trees in bootstrap resamples of the training data
However, the Random Forest algorithm does not natively handling missing data. We need to handle missing data manually during feature engineering. We will impute
Let’s now fit the model configurations defined by the grid_rf using tune_grid()
ranger gives you a lot of additional control by changing defaults in set_engine().
We will mostly use defaults
You should explore if you want to get the best performance from your models
see ?ranger
Defaults for splitting rules are gini for classification and variance for regression. These are appropriate
We will explicitly specify respect.unordered.factors = "order" as recommended. Could consider respect.unordered.factors = "partition"
We will set oob.error = FALSE. TRUE would allow for OOB performance estimate using OOB for each bootstrap for each base learner. We calculate this ourselves using tune_grid()
We will set seed = to generate reproducible bootstraps
We used these plots to confirm that we had selected good combinations of hyperparameters to tune and that the best hyperparameters are inside the range of values considered (or at their objective edge)
Code
# autoplot(fits_rf)
But more importantly, look at the additional reduction in OOB RMSE for Random Forest relative to bagged trees!
Code
show_best(fits_rf)
Warning in show_best(fits_rf): No value of `metric` was given; "rmse" will be
used.
# A tibble: 5 × 9
mtry trees min_n .metric .estimator mean n std_err
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl>
1 20 750 1 rmse standard 24979. 10 710.
2 20 750 2 rmse standard 24980. 10 711.
3 20 1000 1 rmse standard 24981. 10 713.
4 20 1000 2 rmse standard 24991. 10 716.
5 20 500 1 rmse standard 24997. 10 717.
.config
<chr>
1 Preprocessor1_Model41
2 Preprocessor1_Model42
3 Preprocessor1_Model57
4 Preprocessor1_Model58
5 Preprocessor1_Model25
Let’s fit the best model configuration to all the training data
We will use the same seed and other arguments as before
We could now use this final model to predict into our Ames test set (but we will skip that step) to get a better estimate of true performance with new data.
Warning in select_best(fits_rf): No value of `metric` was given; "rmse" will be used.
No value of `metric` was given; "rmse" will be used.
No value of `metric` was given; "rmse" will be used.
In conclusion:
Random Forest is a great out of the box statistical algorithm for both classification and regression
We see no compelling reason to use bagged trees because Random Forest has all (except missing data handling) the benefits of bagged trees plus better prediction b/c of the de-correlated base learners
In some instances, we might use a decision tree if we wanted an interpretable tree as a method to understand rule based relationships between our features and our outcome.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2023. An Introduction to Statistical Learning: With Applications in R. 2nd ed. Springer Texts in Statistics. Springer-Verlag.