Post questions to the video-lectures channel in Slack
1.1.4 Application Assignment and Quiz
No application assignment this unit!
The unit quiz is due by 8 pm on Wednesday January 24th
1.2 An Introductory Framework for Machine Learning
Machine (Statistical) learning techniques have developed in parallel in statistics and computer science
Techniques can be coarsely divided into supervised and unsupervised approaches
Supervised approaches involve models that predict an outcome using features
Unsupervised approaches involve finding structure (e.g., clusters, factors) among a set of variables without any specific outcome specified
This course will focus primarily on supervised machine learning problems
However supervised approaches often use unsupervised approaches in early stages as part of feature engineering
Examples of supervised approaches include:
Predicting relapse day-by-day among recovering patients with substance use disorders based on cellular communications and GPS.
Screening someone as positive or negative for substance use disorder based on their Facebook activity
Predicting the sale price of a house based on characteristics of the house and its neighborhood
Examples of unsupervised approaches include:
Determining the factor structure of a set of personality items
Identifying subgroups among patients with alcohol use disorder based on demographics, use history, addiction severity, and other patient characteristics
Identifying the common topics present in customer reviews of some new product or app
Supervised machine learning approaches can be categorized as either regression or classification techniques
Most regression and classification techniques can handle categorical predictors
Among the earlier supervised model examples, predicting sale price was a regression technique and screening individuals as positive or negative for substance use disorder was a classification technique
1.3 More Details on Supervised Techniques
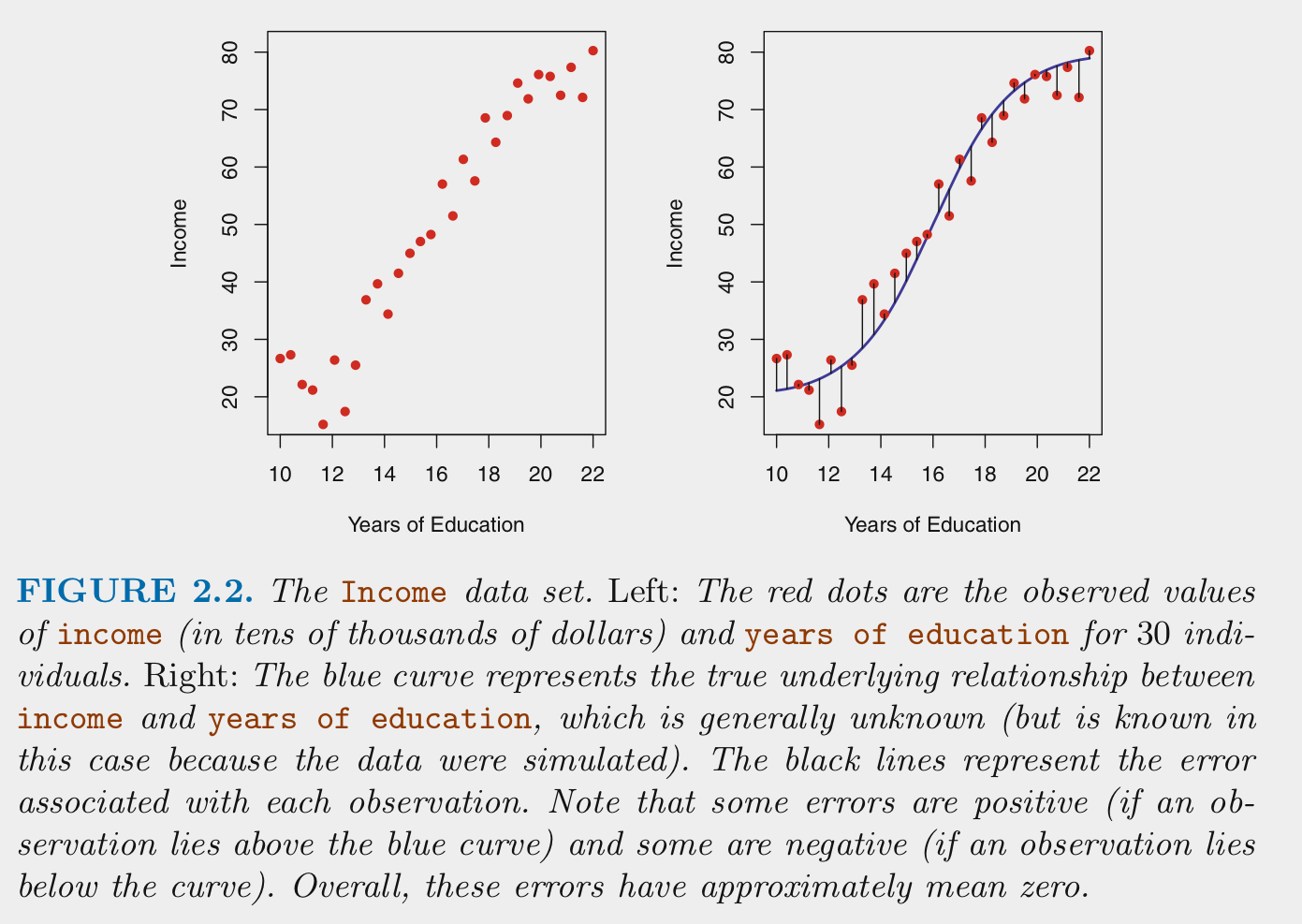
For supervised machine learning problems, we assume \(Y\) (outcome) is a function of some data generating process (DGP, \(f\)) involving a set of Xs (features) plus the addition of random error (\(\epsilon\)) that is independent of X and with mean of 0
\(Y = f(X) + \epsilon\)
Terminology sidebar: Throughout the course we will distinguish between the raw predictors available in a dataset and the features that are derived from those raw predictors through various transformations.
We estimate \(f\) (the DGP) for two main reasons: prediction and/or inference (i.e., explanation per Yarkoni and Westfall, 2017)
\(\hat{Y} = \hat{f}(X)\)
For prediction, we are most interested in the accuracy of \(\hat{Y}\) and typically treat \(\hat{f}\) as a black box
For inference, we are typically interested in the way that \(Y\) is affected by \(X\)
Which predictors are associated with \(Y\)?
Which are the strongest/most important predictors of \(Y\)
What is the relationship between the outcome and the features associated with each predictor. Is the overall relationship between a predictor and \(Y\) positive, negative, dependent on other predictors? What is the shape of relationship (e.g., linear or more complex)?
Does the model as a whole improve prediction beyond a null model (no features from predictors) or beyond a compact model?
We care about good (low error) predictions even when we care about inference (we want small \(\epsilon\))
They will also be tested with low power
Parameter estimates from models that don’t predict well may be incorrect or at least imprecise
Model error includes both reducible and irreducible error.
If we consider both \(X\) and \(\hat{f}\) to be fixed, then:
Irreducible error results from other important \(X\) that we fail to measure and from measurement error in \(X\) and \(Y\)
Irreducible error serves as an (unknown) bounds for model accuracy (without collecting additional Xs)
\([f(X) - \hat{f}(X)]^2\) is reducible
Reducible error results from a mismatch between \(\hat{f}\) and the true \(f\)
This course will focus on techniques to estimate \(f\) with the goal of minimizing reducible error
1.3.1 How Do We Estimate \(f\)?
We need a sample of \(N\) observations of \(Y\) and \(X\) that we will call our training set
There are two types of statistical algorithms that we can use for \(\hat{f}\):
Parametric algorithms
Non-parametric algorithms
Parametric algorithms:
First, make an assumption about the functional form or shape of \(f\).
For example, the general linear model assumes: \(f(X) = \beta_0 + \beta_1*X_1 + \beta_2*X2 + ... + \beta_p*X_p\)
Next, a model using that algorithm is fit to the training set. In other words, the parameter estimates (e.g., \(\beta_0, \beta_1\)) are derived to minimize some cost function (e.g., mean squared error for the linear model)
Parametric algorithms reduce the problem of estimating \(f\) down to one of only estimating some set of parameters for a chosen model
Parametric algorithms often yield more interpretable models
But they are often not very flexible. If you chose the wrong algorithm (shape for \(\hat{f}\) that does not match \(f\)) the model will not fit well in the training set (and more importantly not in the new test set either)
Terminology sidebar: A training set is a subset of your full dataset that is used to fit a model. In contrast, a validation set is a subset that has not been included in the training set and is used to select a best model from among competing model configurations. A test set is a third subset of the full dataset that has not been included in either the training or validation sets and is used for evaluating the performance of your fitted final/best model.
Non-parametric algorithms:
Do not make any assumption about the form/shape of \(f\)
Can fit well for a wide variety of forms/shapes for \(f\)
This flexibility comes with costs
They generally require larger \(N\) in the training set than parametric algorithms to achieve comparable performance
They may overfit the training set. This happens when they begin to fit the noise in the training set. This will yield low error in training set but much higher error in new validation or test sets.
They are often less interpretable
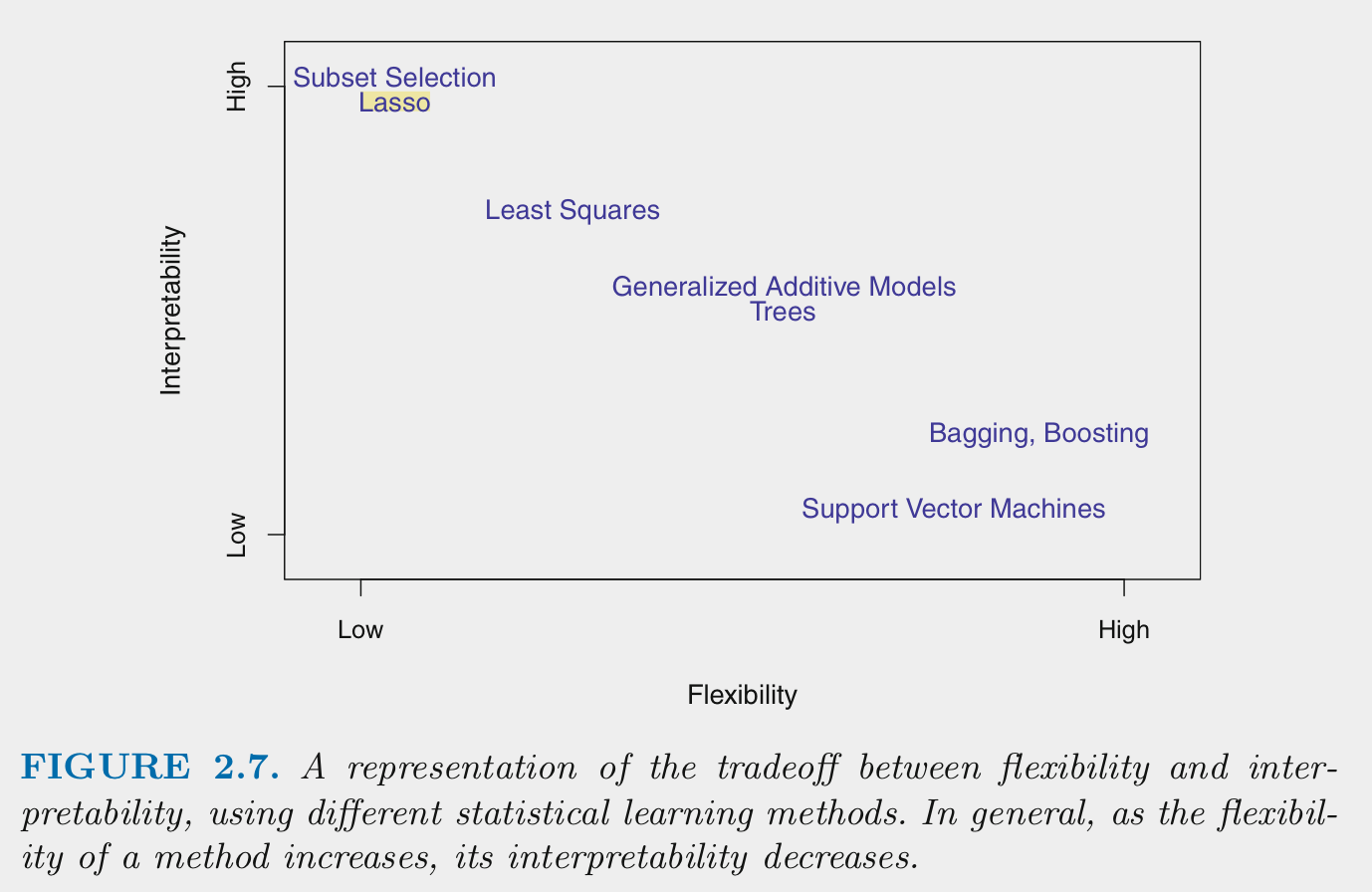
Generally:
Flexibility and interpretability are inversely related
Models need to be flexible enough to fit \(f\) well
Additional flexibility beyond this can produce overfitting
Parametric algorithms are generally less flexible than non-parametric algorithms
Parametric algorithms can become more flexible by increasing the number of features (\(p\) from 610/710; e.g., using more predictors, more complex, non-linear forms to when deriving features from predictors)
Parametric algorithms can be made less flexible through regularization. There are techniques to make some non-parametric algorithms less flexible as well
You want the sweet spot for prediction. You may want even less flexible for inference in increase interpretability.
1.3.2 How Do We Assess Model Performance?
There is no universally best statistical algorithm
Depends on the true \(f\) and your goal (prediction or inference)
We often compare multiple statistical algorithms (various parametric and non-parametric options) and model configurations more generally (combinations of different algorithms with different sets of features)
When comparing models/configurations, we need to both fit these models and then select the best one
Best needs to be defined with respect to some performance metric in new (validation or test set) data
There are many performance metrics you might use
Root Mean squared error (RMSE) is common for regression problems
Accuracy is common for classification problems
We will learn many other performance metrics in a later unit
Two types of performance problems are typical
Models are underfit if they don’t adequately represent the true \(f\), typically because they have oversimplied the relationship (e.g., linear function fit to quadratic DGP, missing key interaction terms)
Underfit models will yield biased predictions. In other words, they will systematically either under-predict or over-predict \(Y\) in some regions of the function.
Biased models will perform poorly in both training and test sets
Models are overfit if they are too flexible and begin to fit the noise in the training set.
Overfit models will perform well (too well actually) in the training set but poorly in test or validation sets
They will show high variance such that the model and its predictions change drastically depending on the training set where it is fit
More generally, these problems and their consequences for model performance are largely inversely related
This is known as the Bias-Variance trade-off
We previously discussed reducible and irreducible error
Reducible error can be parsed into components due to bias and variance
Goal is to minimize the sum of bias and variance error (i.e., the reducible error overall)
We will often trade off a little bias if it provides a big reduction in variance
But before we dive further into the Bias-Variance trade-off, lets review some key terminology that we will use throughout this course.
1.4 Key Terminology in Context
In the following pages:
We will present the broad steps for developing and evaluating machine learning models
We will situate key terms in this context (along with other synonymous terms used by others) and highlight them in bold.
Machine learning has emerged in parallel from developments in statistics and computer science.
As a result, there is a lot of terminology and often multiple terms used for the same concept. This is not my fault!
I will try to use one set of terms, but you need to be familiar with other terms you will encounter
When developing a supervised machine learning model to predict or explain an outcome (also called DV, label, output):
Our goal is for the model to match as close as possible (given the limits due to irreducible error) the true data generating process for Y.
We typically consider multiple (often many) candidate model configurations to achieve this goal.
Candidate model configurations can vary with respect to:
the statistical algorithm used
the algorithm’s hyperparameters
the features used in the model to predict the outcome
Statistical algorithms can be coarsely categorized as parametric or non-parametric.
But we will mostly focus on a more granular description of the specific algorithm itself
Examples of specific statistical algorithms we will learn in this course include the linear model, generalized linear model, elastic net, LASSO, ridge regression, neural networks, KNN, random forest.
The set of candidate model configurations often includes variations of the same statistical algorithm with different hyperparameter (also called tuning parameter) values that control aspects of the algorithm’s operation.
Examples include \(k\) in the KNN algorithm and \(lambda\) in LASSO, Ridge and Elastic Net algorithms.
We will learn more about hyperparameters and their effects later in this course.
The set of candidate model configurations can vary with respect to the features that are included.
A recipe describes how to transform raw data for predictors (also called IVs) into features (also called regressors, inputs) that are included in the feature matrix (also called design matrix, model matrix).
This process of transforming predictors into features in a feature matrix is called feature engineering.
Crossing variation on statistical algorithms, hyperparameter values, and alternative sets of features can increase the number of candidate model configurations dramatically
developing a machine learning model can easily involve fitting thousands of model configurations.
In most implementations of machine learning, the number of candidate model configurations nearly ensures that some fitted models will overfit the dataset in which they are developed such that they capitalize on noise that is unique to the dataset in which they were fit.
For this reason, model configurations are assessed and selected on the basis of their relative performance for new data (observations that were not involved in the fitting process).
We have ONE full dataset but we use resampling techniques to form subsets of that dataset to enable us to assess models’ performance in new data.
Cross-validation and bootstrapping are both examples of classes of resampling techniques that we will learn in this course.
Broadly, resampling techniques create multiple subsets that consist of random samples of the full dataset. These different subsets can be used for model fitting, model selection, and model evaluation.
Training sets are subsets that are used for model fitting (also called model training). During model fitting, models with each candidate model configuration are fit to the data in the training set. For example, during fitting, model parameters are estimated for regression algorithms, and weights are established for neural network algorithms. Some non-parametric algorithms, like k-nearest neighbors, do not estimate parameters but simply “memorize” the training sets for subsequent predictions.
Validation sets are subsets that are used for model selection (or, more accurately, for model configuration selection). During model selection, each (fitted) model — one for every candidate model configuration — is used to make predictions for observations in a validation set that, importantly, does not overlap with the model’s training set. On the basis of each model’s performance in the validation set, the relatively best model configuration (i.e., the configuration of the model that performs best relative to all other model configurations) is identified and selected. If you have only one model configuration, validation set(s) are not needed because there is no need to select among model configurations.
Test sets are subsets that are used for model evaluation. Generally, a model with the previously identified best configuration is re-fit to all available data other than the test set. This fitted model is used to predict observations in the test set to estimate how well this model is expected to perform for new observations.
There are three broad steps to develop and evaluate a machine learning model:
Fitting models with multiple candidate model configurations (in training set(s))
Assessing each model to select the best configuration (in validation set(s))
Evaluating how well a model with that best configuration will perform with new observations (in test sets(s))
1.5 An Example of the Bias-Variance Trade-off
1.5.1 Overview of Example
The concepts of underfitting vs. overfitting and the bias-variance trade-off are critical to understand
It is also important to understand how model flexibility can affect both the bias and variance of that model’s performance
It can help to make these abstract concepts concrete by exploring real models that are fit in actual data
We will conduct a very simple simulation to demonstrate these concepts
The code in this example is secondary to understanding the concepts of underfittinng, overfitting, bias, variance, and the bias-variance trade-off
We will not display much of it so that you can maintain focus on the concepts
You will have plenty of time to learn the underlying
When modeling, our goal is typically to approximate the data generating process (DGP) as close as possible, but in the real world we never know the true DGP.
A key advantage of many simulations is that we do know the DGP because we define it ourselves.
For example, in this simulation, we know that \(Y\) is a cubic function of \(X\) and noise (random error).
In fact, we know the exact equation for calculating \(Y\) as a function of \(X\).
We will attempt to model this cubic DGP with three different model configurations
A simple linear model that uses only \(X\) as a feature
A (20th order) polynomial linear model that uses 20 polynomials of \(X\) as features
A (20th order) polynomial LASSO model that uses the same 20 polynomials of \(X\) as features but “regularizes” to remove unimportant features from the model
Question: If the DGP for y is a cubic function of x, what do we know about the expected bias for our three candidate model configurations in this example?
Show Answer
The simple linear model will underfit the true DGP and therefore it will be biased b/c it can only represent Y as a linear function of X. The two polynomial models will be generally unbiased b/c they have X represented with 20th order polynomials. LASSO will be slightly biased due to regularization but more on that in a later unit
1.5.2 Stimulation Steps
With that introduction complete, lets start our simulation of the bias-variance trade-off
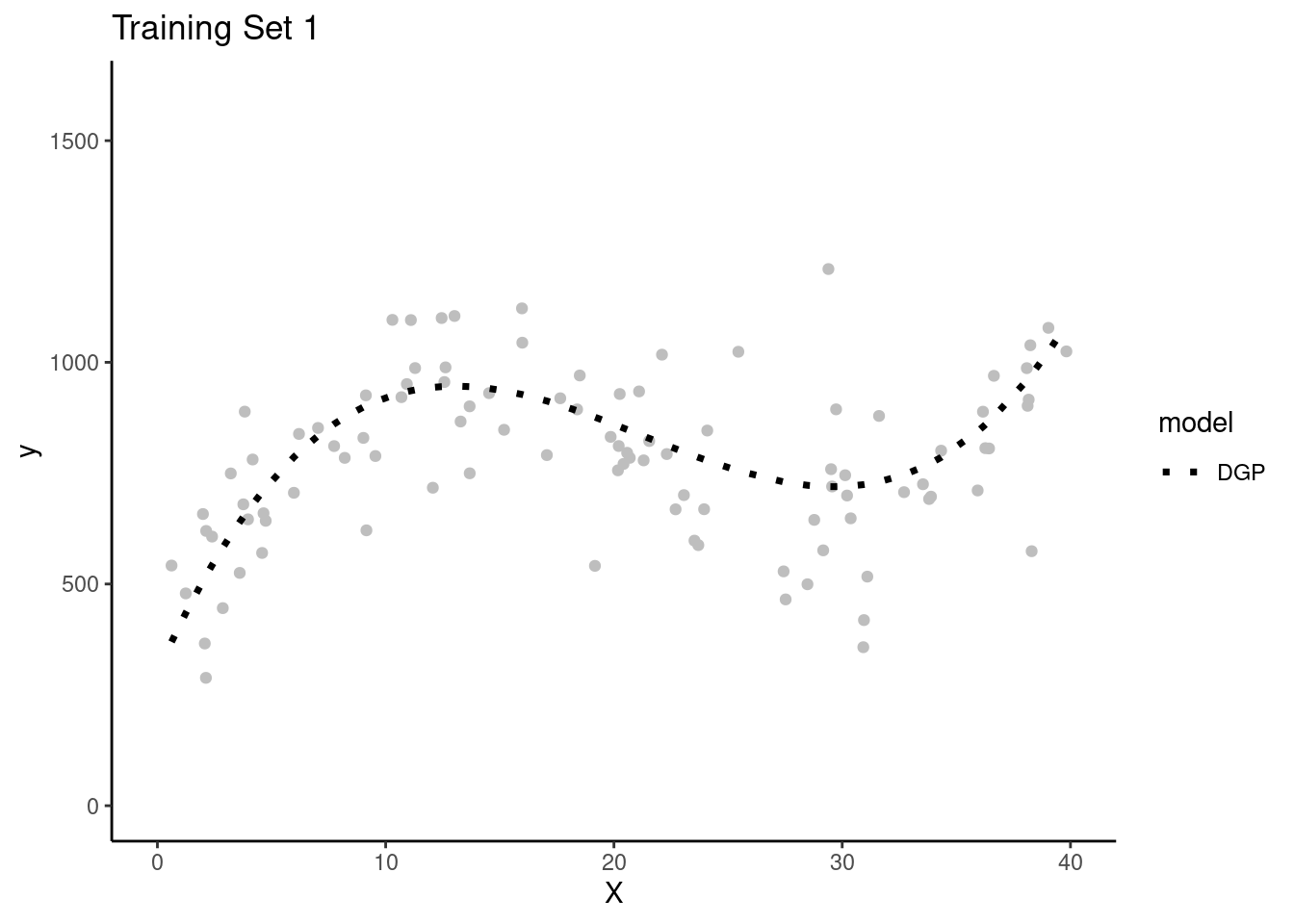
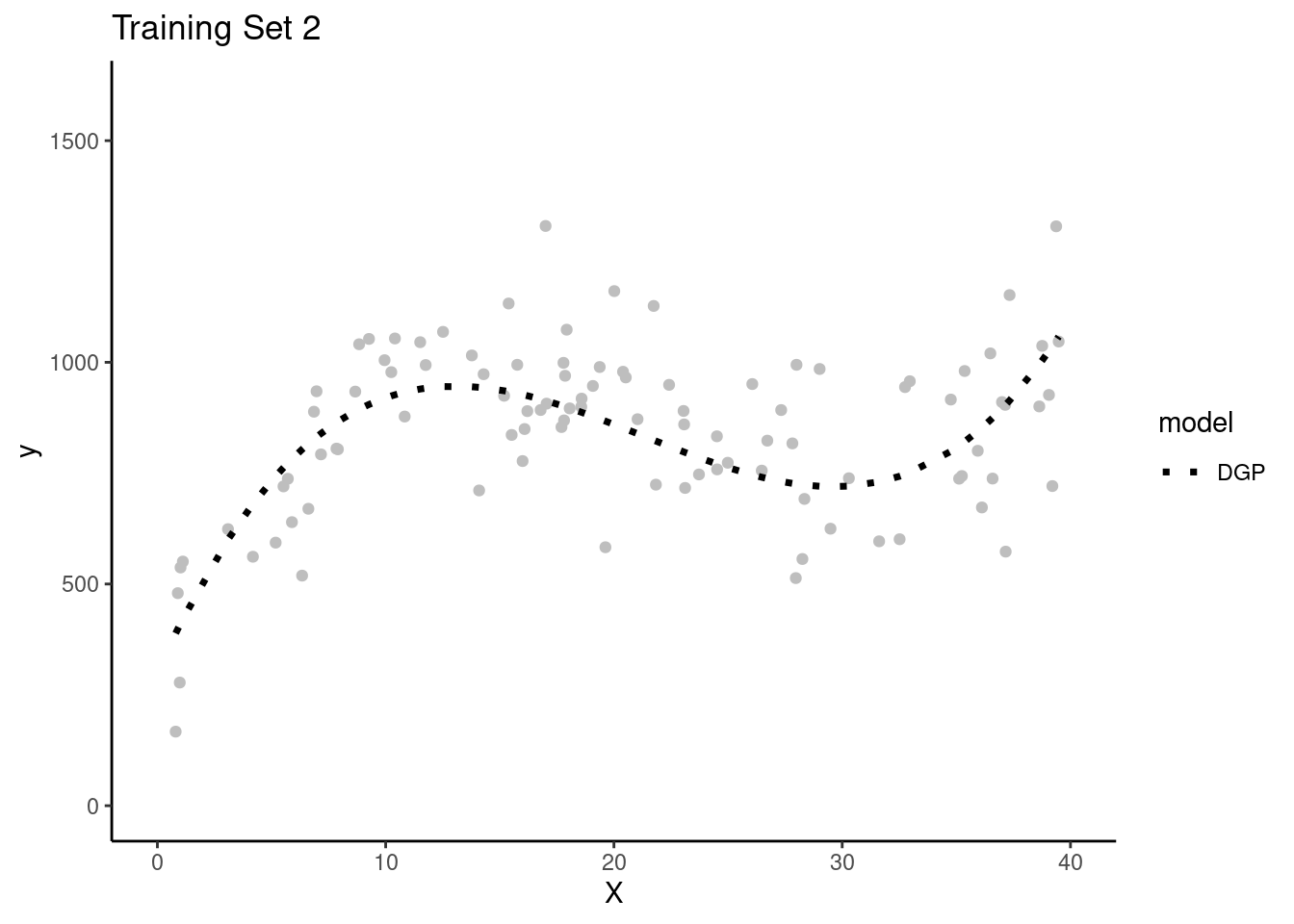
Lets simulate four separate research teams, each working to estimate the DGP for Y
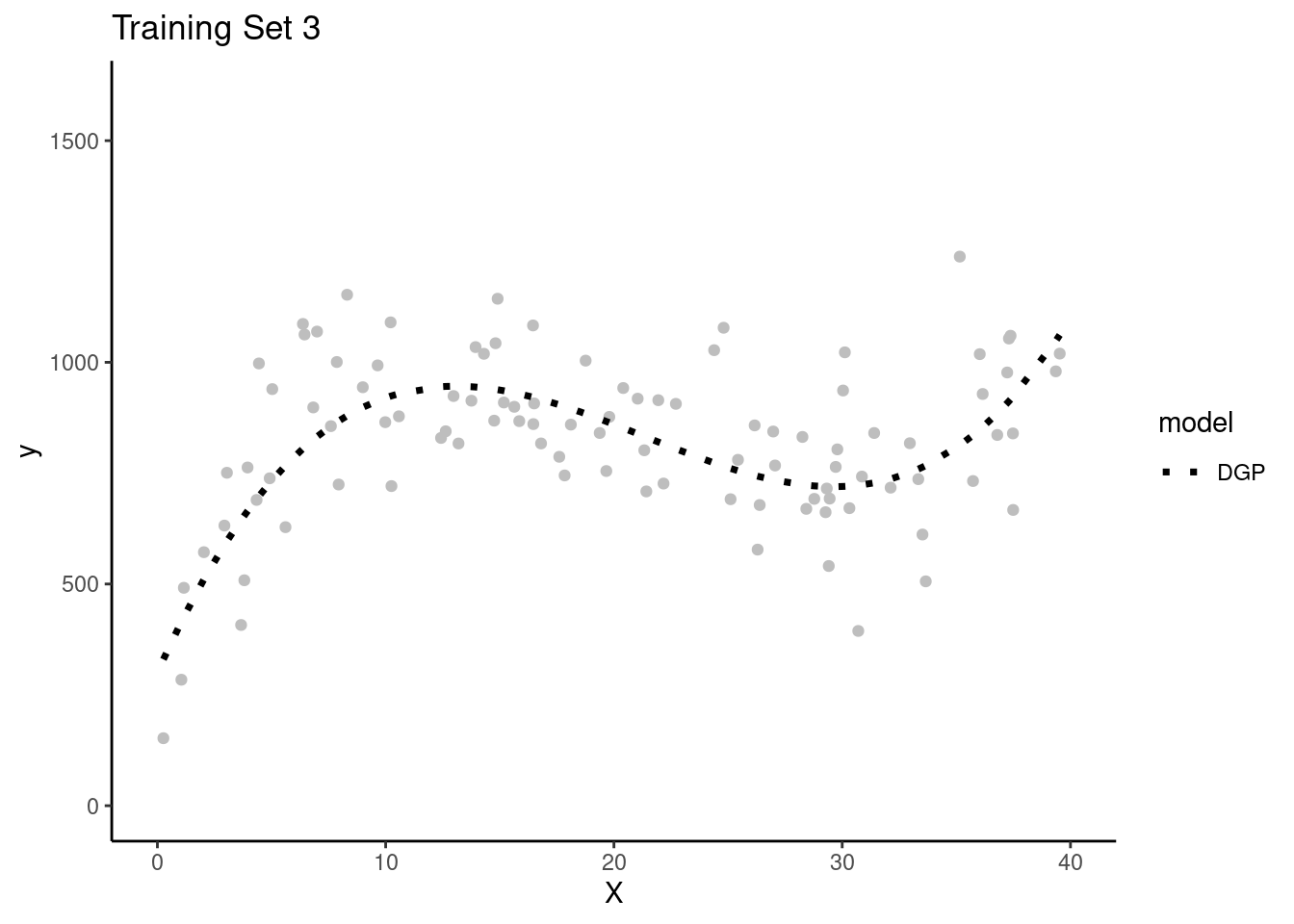
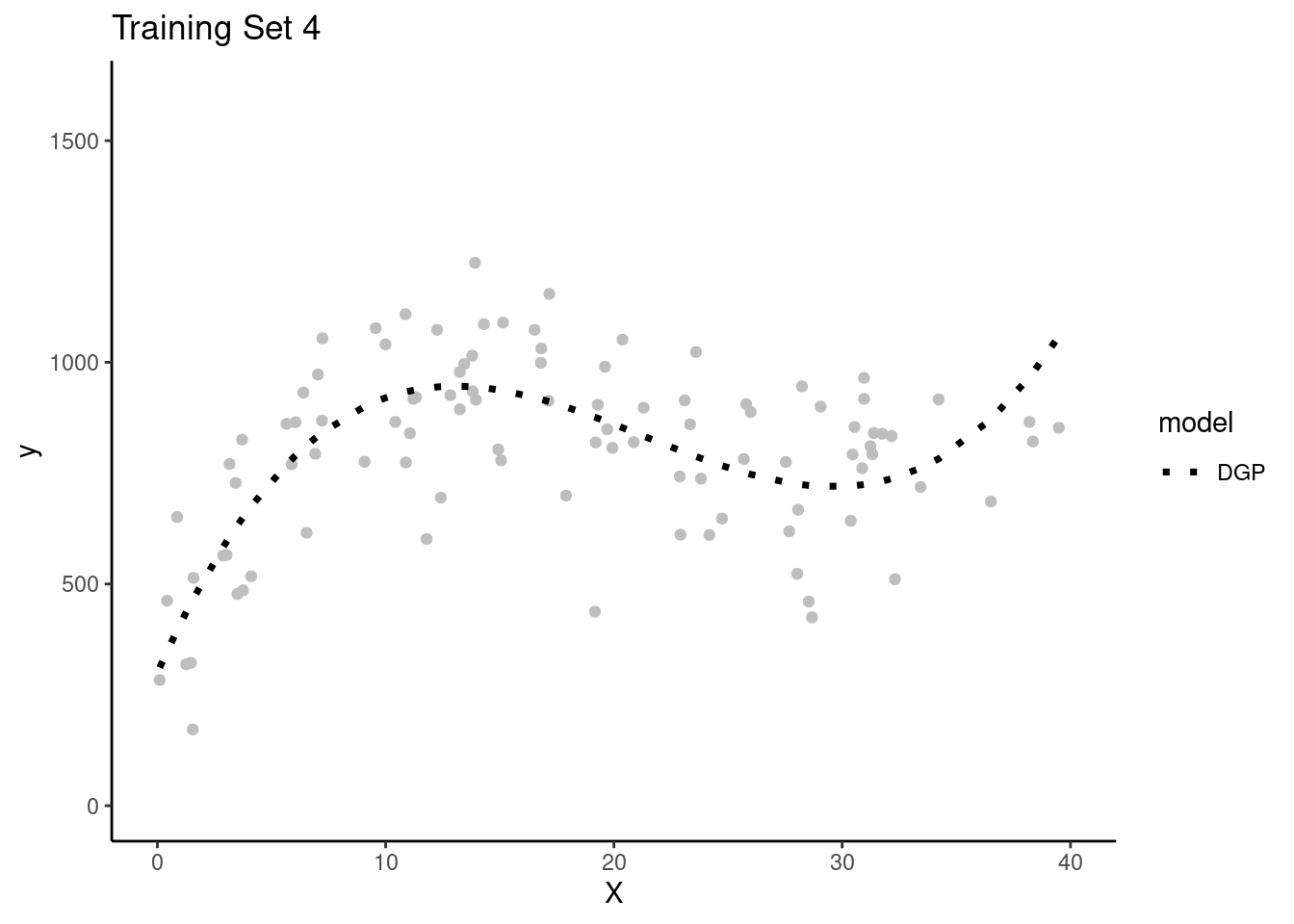
Each team will get their own random sample of training data (N = 100) to fit models
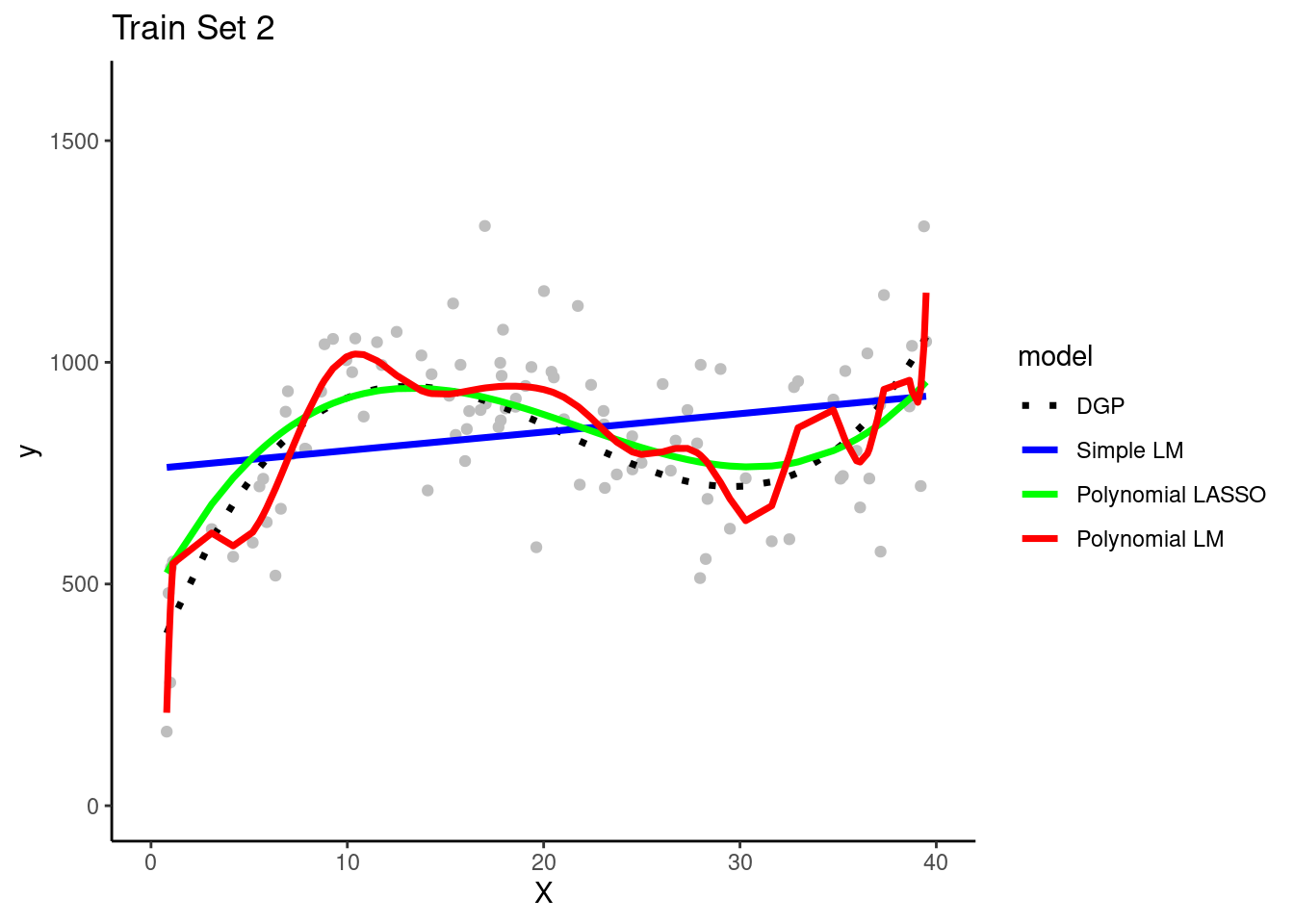
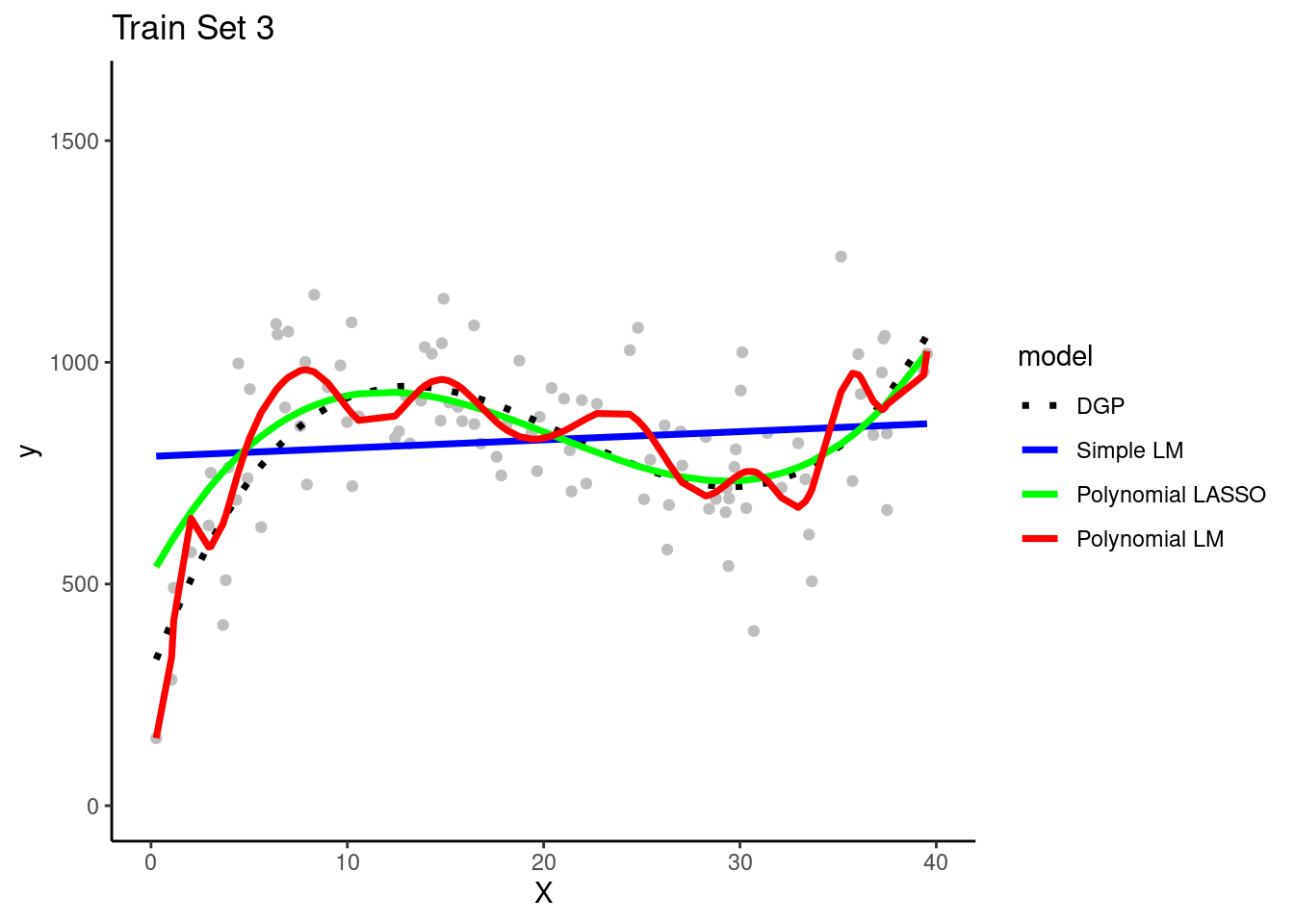
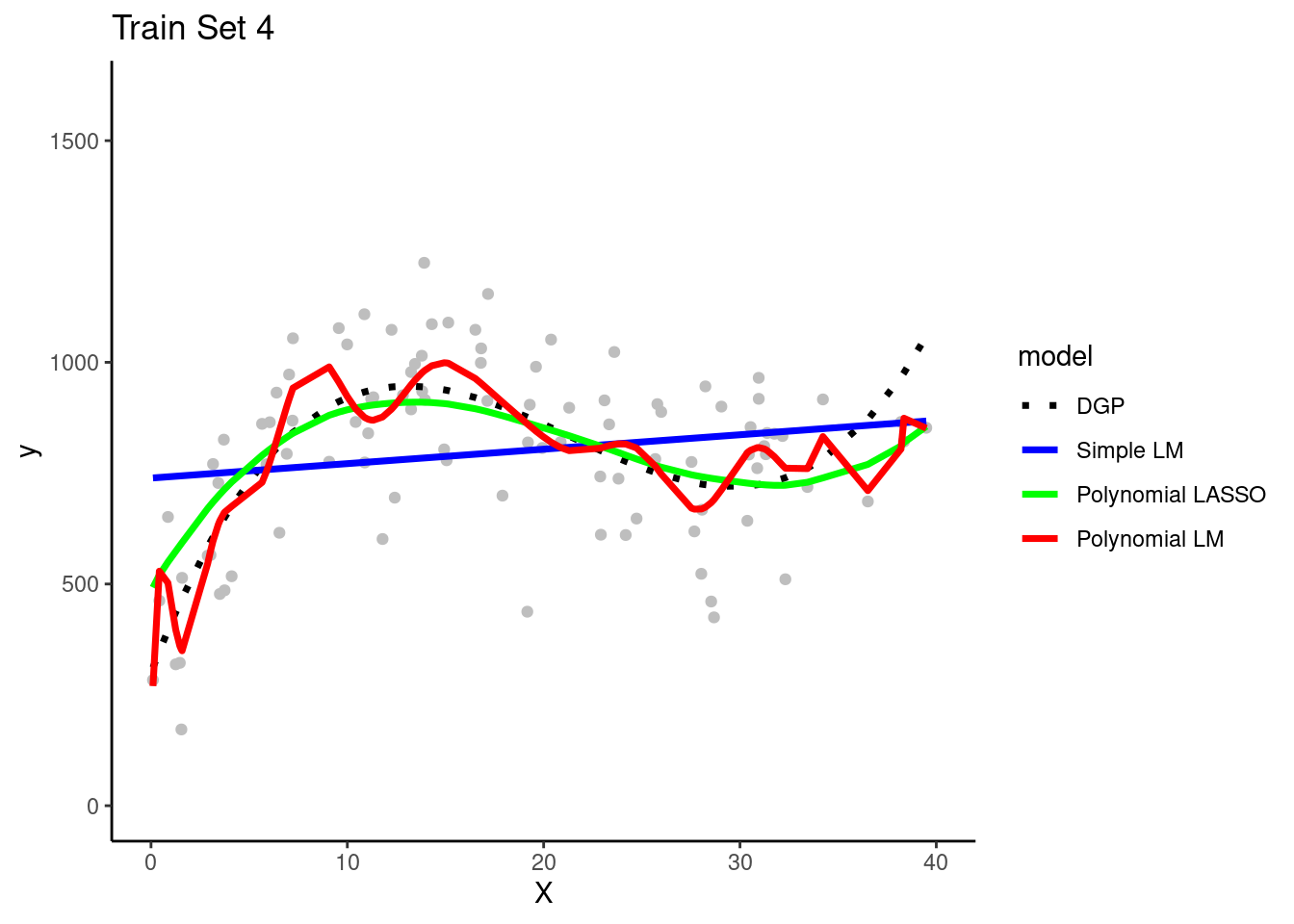
Here are plots of these four simulated training sets (one for each team) with a dotted line for the data generating process (DGP)
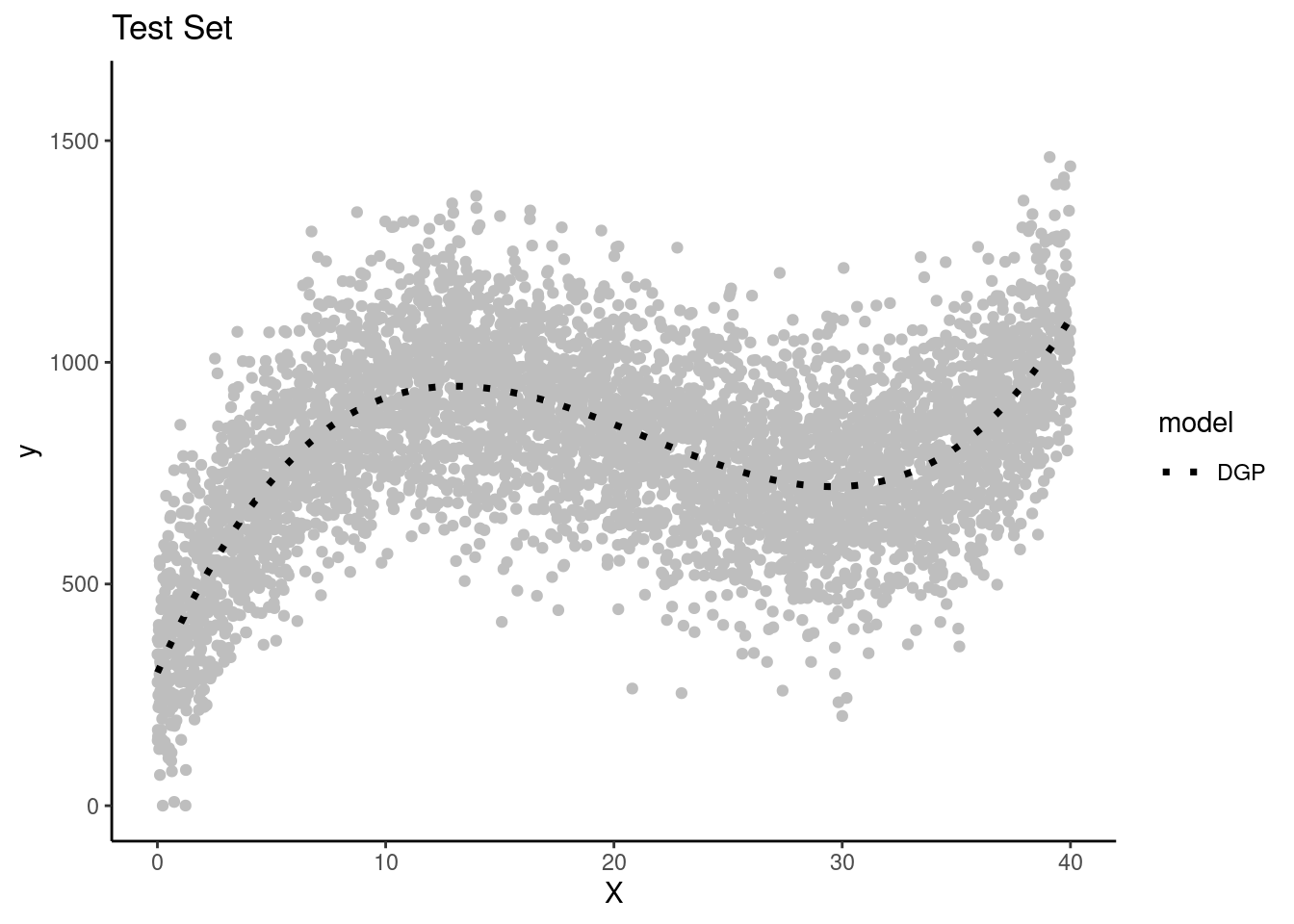
We get one more large random sample (N = 5000) with the same DGP to use as a test set to evaluate all the models that will be fit in the separate training sets across the four teams.
We will let each team use this same test set to keep things simple
The key is that the test set contains new observations not present in any of the training sets
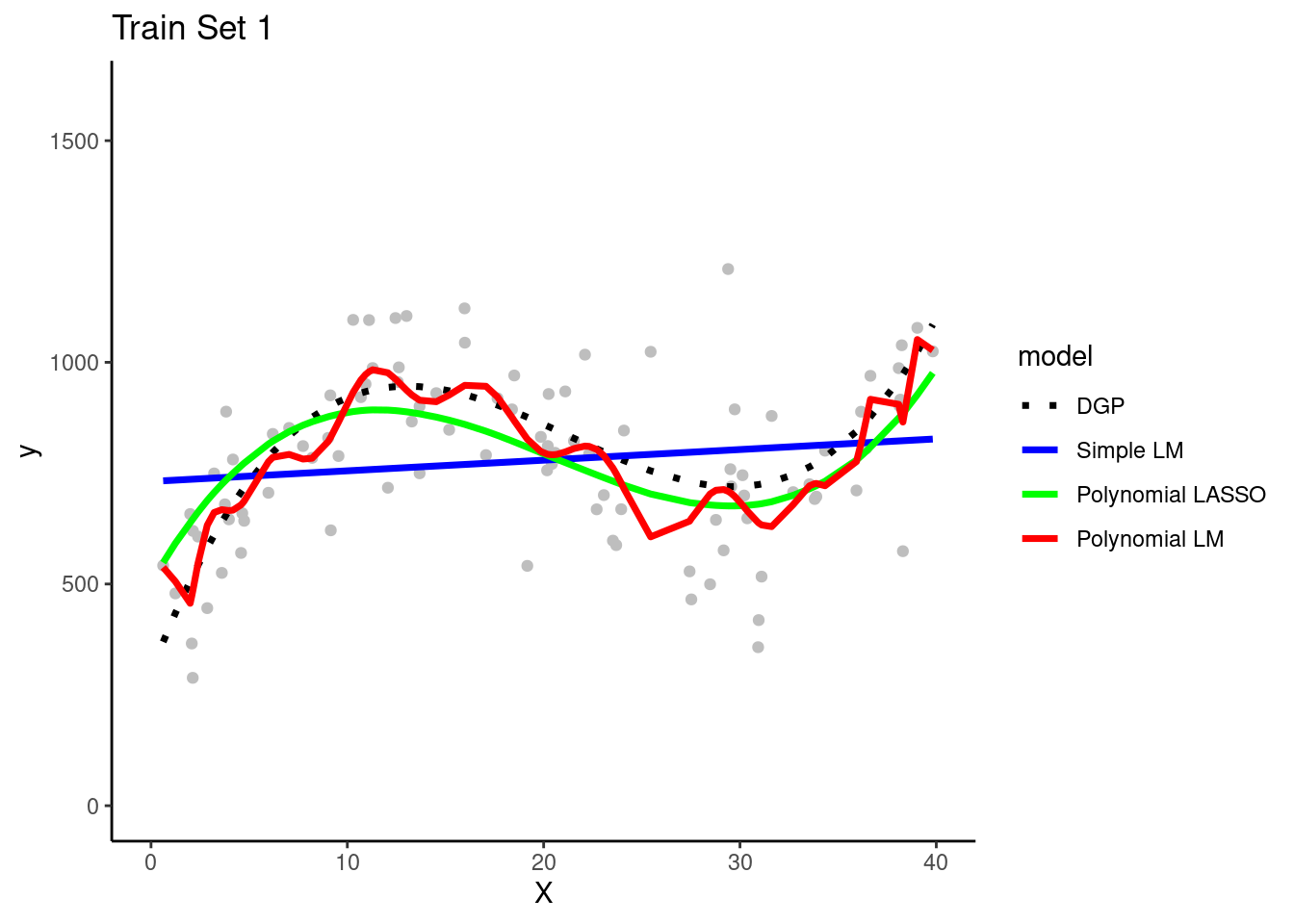
Each of the four teams fit their three model configurations in their training sets
They use the resulting models to make predictions for observations in the same training set in which they were fit
Question: Can you see evidence of bias for any model configuration? Look in any training set.
Show Answer
The simple linear model is clearly biased. It systemically underestimates Y in some portions of the X distribution and overestimates Y in other portions of the X distribution. This is true across training sets for all teams.
Question: Can you see any evidence of overfitting for any model configuration?
Show Answer
The polynomial linear model appears to overfit the data in the training set. In other words, it seems to follow both the signal/DGP and the noise. However, in practicenone of the teams could not be certain of this with only their training set. It ispossible that the wiggles in the prediction line represent the real DGP. They needto look at the model's performance in the test set to be certain about the degree ofoverfitting. (Of course, we know because these are simulated data and we know the DGP.)
Now the teams use their 3 trained models to make predictions for new observations in the test set
Remember that the test set has NEW observations of X and Y that weren’t used for fitting any of the models.
Lets look at each model configuration’s performance in test separately
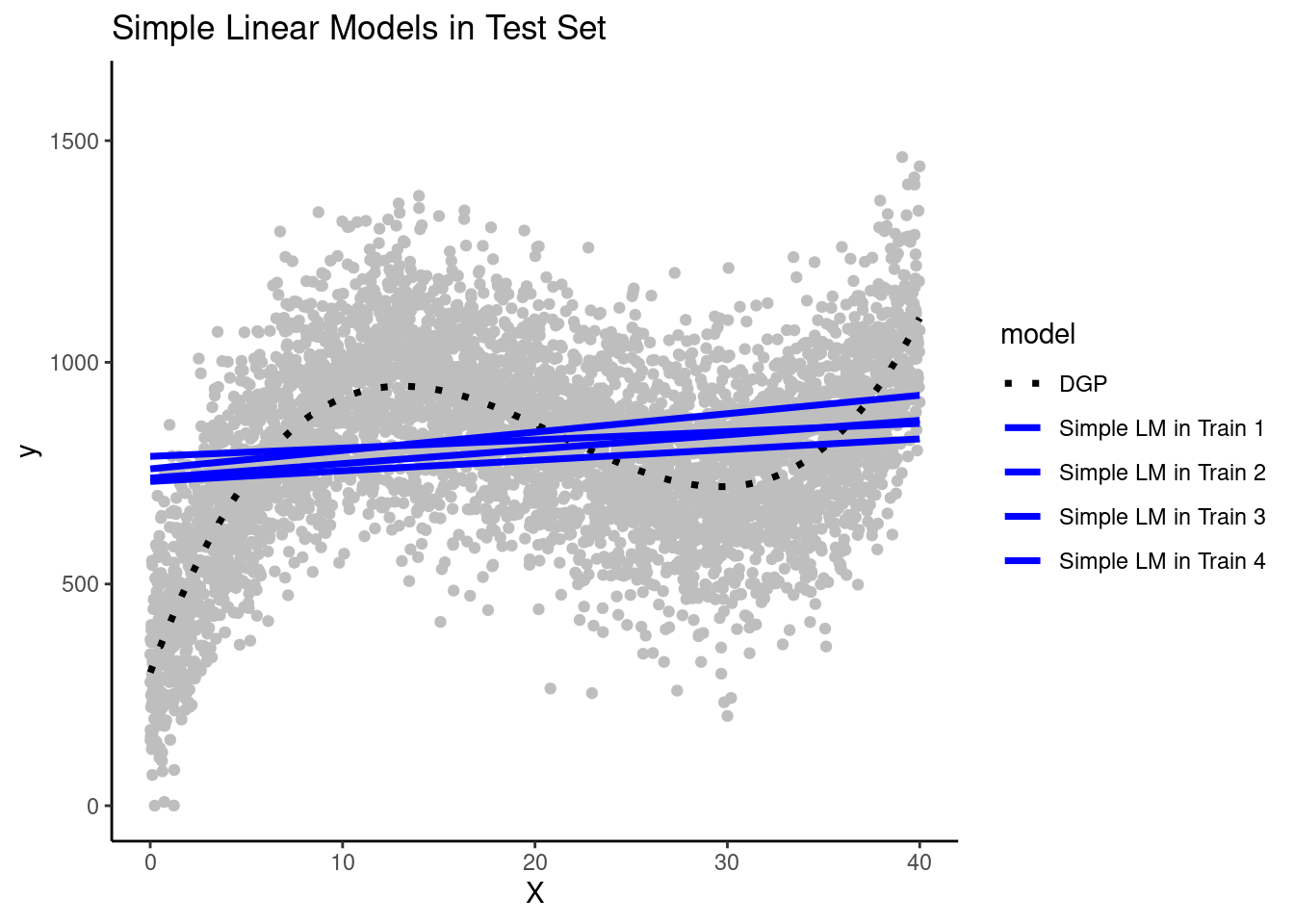
Here are predictions from the four simple linear models (fit in the training sets for each team) in the test set
Question: Can you see evidence of bias for the simple linear models?
Show Answer
Yes, consistent with what we saw in the training sets, the simple linear modelsystematically overestimates Y in some places and underestimates it in others. The DGP is clearly NOT linear but this simple model can only make linear predictions.It is a fairly biased model that underfits the true DGP. This bias will make a large contribution to the reducible error of the model
Question: How much variance across the simple linear models is present?
Show Answer
There is not much variance in the prediction lines across the models that were fit by different teams in different training sets. The slopes are very close acrossthe different team's models and the intercepts only vary by a small amount. The simple linear model configuration does not appear to have high variance (across teams) and therefore model variance will not contribute much to its reducible error.
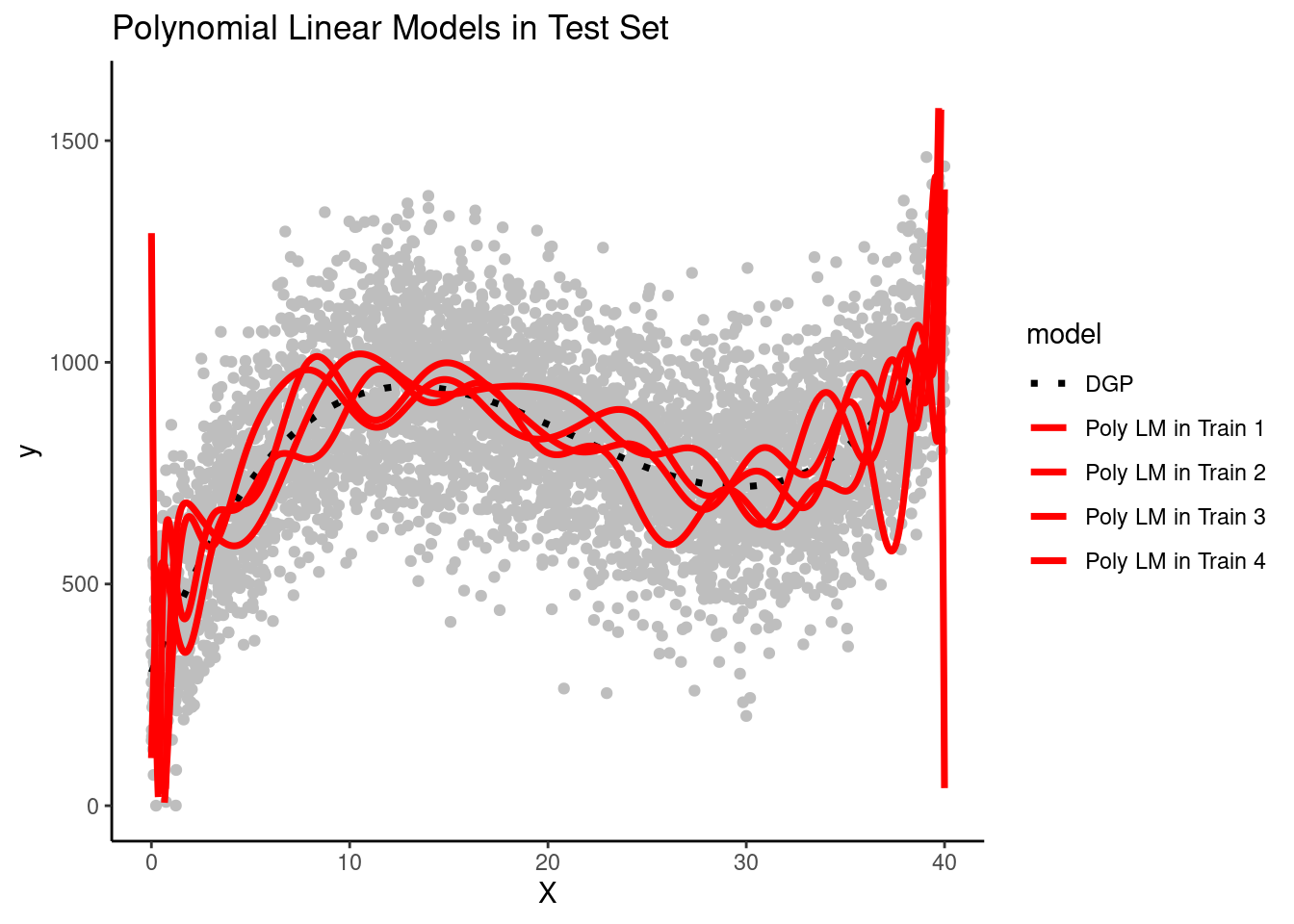
Here are predictions from the polynomial linear models from the four teams in the test set
Question: Are these polynomial models systematically biased?
Show Answer
There is not much systematic bias. The overall function is generally cubic for all four teams - just like the DGP. Bias will not contribute much to the model's reducible error.
Question: How does the variance of these polynomial models compare to the variance of the simple linear models?
Show Answer
There is much higher model variance for this polynomial linear model relative to the simple linear model. Although all four models generally predict Y as a cubicfunction of X, there is also a non-systematic wiggle that is different for each team's models.
Question: How does this demonstrate the connection between model overfitting and model variance?
Show Answer
Model variance (across teams) is a result of overfitting to the training set. If a model fits noise in its training set, that noise will be different in every dataset.Therefore, you end up with different models depending on the training set in which they are fit. And none of those models will do well with new data as you can see in thistest set because noise is random and different in each dataset.
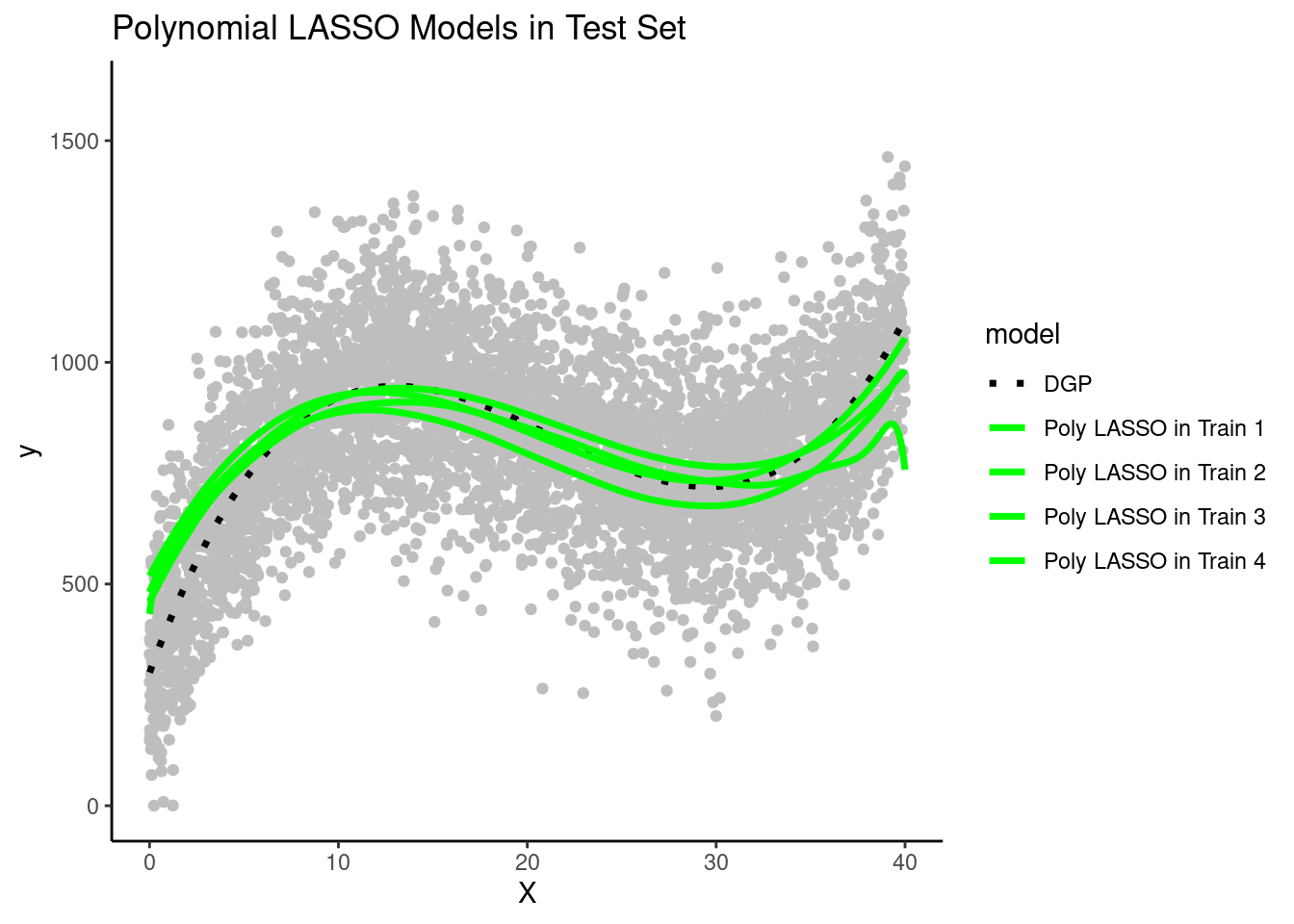
Here are predictions from the polynomial LASSO models from each team in the test set
Question: How does their bias compare to the simple and polynomial linear models?
Show Answer
The LASSO models have low bias much like the polynomial linear model. They are able to capture the true cubic DGP fairly well. The regularization process slightly reduced themagnitude of the cubic (the prediction line is a little straighter than it should be),but not by much.
Question: How does their variance compare to the simple and polynomial linear models?
Show Answer
All four LASSO models, fit in different training sets, resulted in very similar prediction lines. Therefore, these LASSO models have low variance, much like the simple linear model. In contrast, the LASSO model variance is clearly lower than the more flexible polynomimal model.
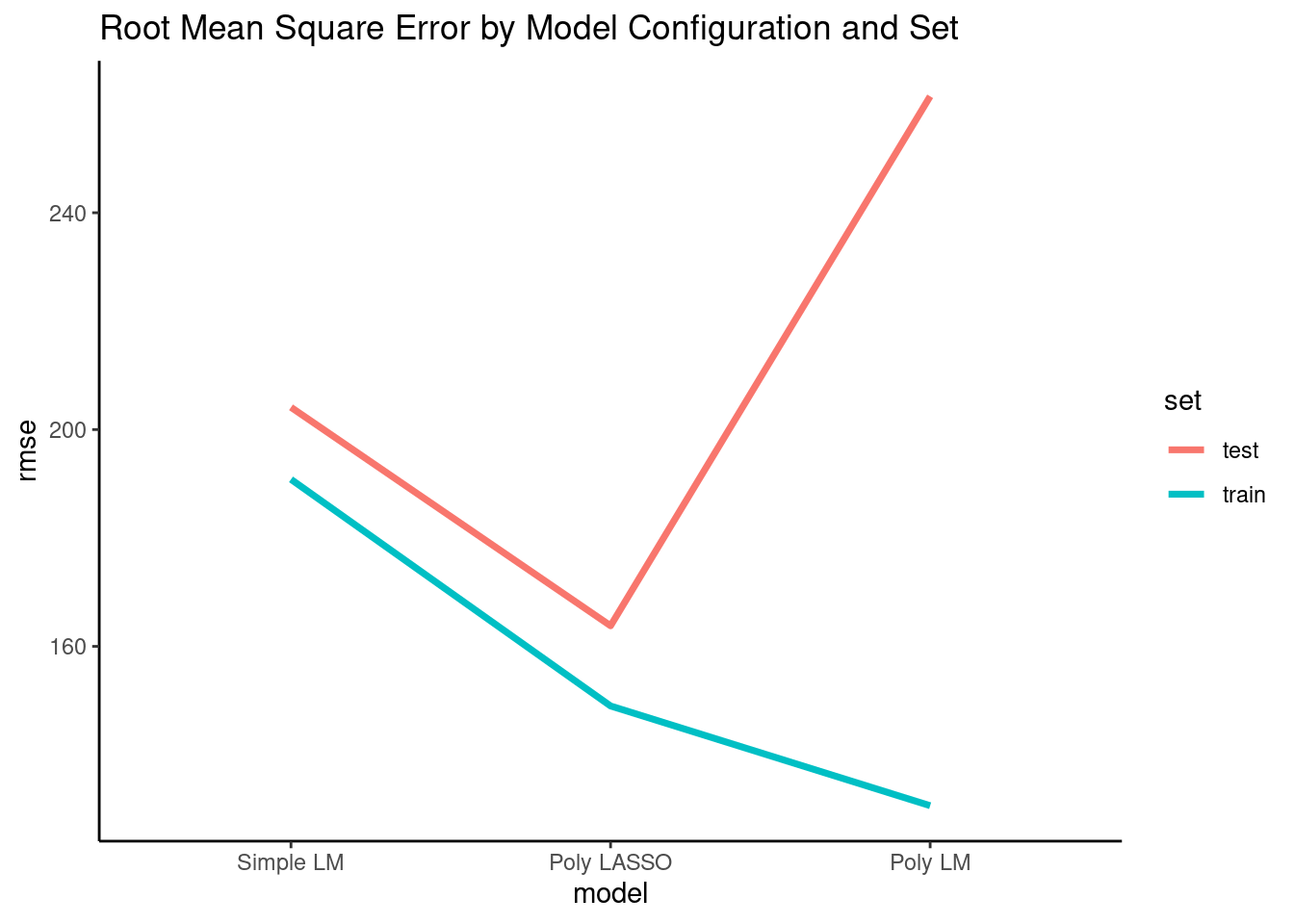
Now we will quantify the performance of these models in training and test sets with the root mean square error performance metric. This is the standard deviation of the error when comparing the predicted values for Y to the actual values (ground truth) for Y.
Question: What do we expect about RMSE for the three models in train and test?
Show Answer
The simple linear model is underfit to the TRUE DGP. Therfore it is systematically biased everywhere it is used. It won't fit well in train or test for this reason. However, it’s not very flexible so it won’t be overfit to the noise in train and therefore should fit comparably in train and test. The polynomial linear model will not be biased at all given that the DGP is polynomial. However, it is overly flexible (20th order) and so will substantially overfit the training data such that it will show high variance and its performance will be poor in test. The polynomial LASSO will be the sweet spot in bias-variance trade-off. It has a little bias but not much. However, it is not as flexible due to regularizationby lambda so it won’t be overfit to its training set. Therefore, it should do well in the test set.
To better understand this:
Compare RMSE across the three model configurations within the training sets (turquoise line)
Compare how RMSE changes for each model configuration across its training set and the test set
Compare RMSE across the three model configurations within the test set (red line)?
Specifically compare the performance of simple linear model (least flexible) with the polynomial linear model (most flexible)
Question: Would these observations about bias and variance of these three model configurations always be the same regardless of the DGP?
Show Answer
No. A model configuration needs to be flexible enough and/or well designed to represent the DGP for the data that you are modeling. The two polynomial modelsin this example were each able to represent a cubic DGP. The simple linear modelwas not. The polynomial linear model was too flexible for a cubic given that it had 20 polynomials of X. Therefore, it was overfit to its training set and had high variance. However, if the DGP was a different shape, the story would be different. If the DGP was linear the simple linear model would not have been biased and would have performed best. If this DGP was some other form (step function),it may be that none of the models would work well.
1.6 Discussion - Tuesday/Thursday
1.6.1 Course Overview
Introductions (preferred name, pronouns, program/department and year)
Structure of course
Same flow each week
Week starts on Thursdays at 12:15 pm
Assignments include:
Pre-recorded lectures
Web book material
Readings (James et al. (2023) and other sources; All free)
Application assignment
Asychronous discussion and questions on Slack
Lab section on Tuesdays at 11:00 am - address previous week’s code
Quiz and application assignments due Wednesdays at 8 pm
Wrap-up discussion and conceptual questions on Thursdays at 11 am. Not a lecture
Self-paced (except for due dates and discussion)
Quizzes used to encourage and assess reading. Also to guide discussion.
Workload similar to 610/710
Office hours
John - Thursdays, 1 – 2 pm
Michelle - Wednesdays, 10 - 11 am
Kendra - Mondays, 2:30 - 3:30 pm
Personal appointments & Slack
The web book
Primary source for all course materials
Organized by units (with syllabus at front)
Links to pre-recorded lectures, readings, and quiz
Provides primary source for code examples (all you need for this course)
Lecture follows book
Course as guided learning
Concepts in lectures and readings
Applications in web book and application assignment
Discussion section is discussion/questions (not pre-planned lecture)
Slack CAN be a good source for discussion and questions as well
Grades are secondary (quizzes, application assignments, exams)
Why these tools?
Quarto
Scientific publishing system (reproducible code, with output, presentations, papers)
Tool for collaboration
Interactive with static product (render to html or pdf)
Application assignments, web book, and slides
tidyverse?
The tidyverse is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures
Unmatched for data wrangling, EDA, and data visualization
tidymodels?
Consistent interface to hundreds of statistical algorithms
Yay! May develop into an amazing tool in your workflow
Use as tool (like Stack Overflow) for applications (application assignments, application questions on exams)
Check carefully - it can be wrong even when it looks right
Do NOT use for conceptual questions (quizzes, conceptual exam questions). This type of info needs to be in your head to be effective data scientist.
Academic Integrity
Do not cheat! Only you lose.
No collaboration with classmates, peers, previous students on anything graded (including application assignments)
All cheating reported to Department and Dean of Students. If application assignment or quizzes, zero on all of them because I can’t trust them. If exam, zero on exam.
1.6.2 Association vs. Prediction
Question: What is the difference between association vs. prediction?
Show Answer
Association quantifies the relationship between variables within a sample (predictors-outcome). Prediction requires using an established model to predict (future?) outcomes for new ("out-of-sample, "held-out") participants.
Much research in psychology demonstrates association but calls it prediction!
Association (sometimes substantially) overestimates the predictive strength of our models
Coefficients are derived to mimimize SSE (or maximize \(R^2\))
\(R^2\) from GLM (using one sample) indexes how well on average any GLM that is fit to a sample will account for variance in that sample when specific coefficients are estimated in the same sample they are evaluated
\(R^2\) does NOT tell you how well a specific GLM (including its coefficients) will work with new data for prediction
\(R^2\) itself is positively biased even as estimate of how well a sample specific GLM will predict in that sample (vs. adjusted \(R^2\) and other corrections)
1.6.3 Prediction vs. Explanation
Examples of valuable prediction without explanation?
Can you have explanation without prediction?
Prediction models can provide insight or tests of explanatory theories (e.g., do causes actually predict in new data; variable importance)
Goal of scientific psychology is to understand human behavior. It involves both explaining behavior (i.e., identifying causes) and predicting (yet to be observed) behaviors.
We overemphasize explanatory goals in this department, IMO
Machine learning is well positioned for prediction, but also for explanation
1.6.4 Basic framework and terminology for machine learning
Supervised vs. unsupervised machine learning?
Supervised regression vs classification?
1.6.5 Data Generating Process
What is a data generating process?
\(Y = f(X) + \epsilon\)
both function and Xs are generally unknown
\(\hat{Y} = \hat{f}(X)\)
Why do we estimate the data generating process?
1.6.6 Cross Validation
What is it and why do we do it?
How are replication and cross-validation different?
Reducible vs. Irreducible error?
Our predictions will have error
You learned to estimate parameters in the GLM to minimize error in 610
But error remained non-zero (in your sample and more importantly with same model in new samples) unless you perfectly estimated the DGP
That error can be divided into two sources
Irreducible error comes from measurement error in X, Y and missing X because predictors (causes) not measured.
Irreducible without collecting new predictors and/or with new measures
It places a ceiling on the performance of the best model you can develop with your available data
Reducible error comes from mismatch between \(\hat{f}(X)\) and the true \(f(X)\).
We can reduce this without new data.
Just need better model (\(\hat{f}(X)\)).
You didn’t consider this (much) in 610 because you were limited to one statistical algorithm (GLM) AND it didn’t have hyperparameters.
You did reduce error by coding predictors (feature engineering) differently (interactions \(X1*X2\), polynomial terms \(X^2\), power transformations of X) This course will teach you methods to decrease reducible error (and validly estimate total error of that best model)
What are the three general steps by which we estimate and evaluate the data generating process with a sample of data? Lets use all this vocabulary!
Candidate model configurations
Statistical algorithms
Hyperparameters
Features (vs. predictors?), feature matrix, feature engineering, recipe (tidymodels specific)
Model fitting (training), selection, and evaluation
Resampling techniques
cross validation techniques (k-fold)
boostrapping for cross validation
Training, validation, and test sets (terms vary in literature!)
1.6.7 Bias-variance tradeoff
What is underfitting, overfitting, bias, and variance?
Bias and variance are general concepts to understand during any estimation process
Estimate mean, median, standard deviation
Parameter estimates in GLM
Estimate DGP - \(\hat{Y} = \hat{f}(X)\)
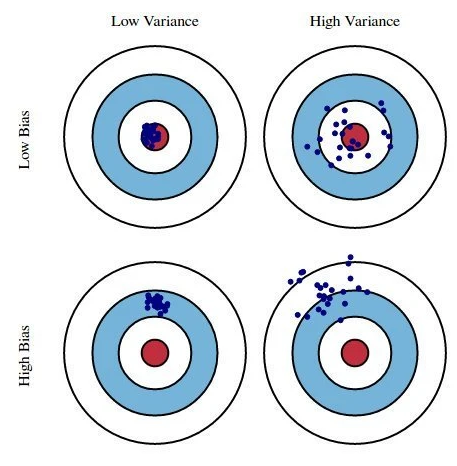
Conceptual example of bias-variance: Darts from Yarkoni and Westfall (2017)
Second Conceptual Example: Models (e.g. many scales made by Acme Co.) to measure my weight
1.6.8 Bias - A deeper dive
Biased models are generally less complex models (i.e., underfit) than the data-generating process for your outcome
Biased models lead to errors in prediction because the model will systematically over- or under-predict outcomes (scores or probabilities) for specific values of predictor(s) (bad for prediction goals!)
Parameter estimates from biased models may over or under-estimate the true effect of a predictor (bad for explanatory goals!)
Question: Are GLMs biased models?
Show Answer
GLM parameter estimates are BLUE - best **linear** unbiased estimators. Parameterestimates from any sample are unbiased estimates of the linear model coefficientsfor population model but if DGP is not linear, this linear model will produce biased predictions and have biased parameter estimates.
Bias seems like a bad thing.
Both bias (due to underfitting) and variance (due to overfitting) are sources of (reducible) prediction errors (and imprecise/inaccurate parameter estimates). They are also often inversely related (i.e., the trade-off).
A model configuration needs to be flexible enough to represent the true DGP.
Any more flexibility will lead to overfitting.
Any less flexibility will lead to underfitting.
Ideally, if your model configuration is perfectly matched to the DGP, it will have very low bias and very low variance (assuming sufficiently large N)
The world is complex. In many instances,
We can’t perfectly represent the DGP
We trade off a little bias for big reduction in variance to produce the most accurate predictions (and stable parameter estimates across samples for explanatory goals)
Or we trade off a little variance (slightly more flexible model) to get a big reduction in bias
Either way, we get models that predict well and may be useful for explanatory goals
1.6.9 Variance - A deeper dive
Question: Consider example of p = n - 1 in general linear model. What happens in this situation? How is this related to overfitting and model flexibility?
Show Answer
The model will perfectly fit the sample data even when there is no relationshipbetween the predictors and the outcome. e.g., Any two points can be fit perfectlywith one predictor (line), any three points can be fit perfectly with two predictors(plane). This model will NOT predict well in new data. This model is overfit because n-1 predictors is too flexible for the linear model. You will fit the noise in the training data.
Factors that increase overfitting
Small N
Complex models (e.g, many predictors, p relative to n, non-parametric models)
Weak effects of predictors (lots of noise available to overfit)
Correlated predictors (for some algorithms like the GLM)
Choosing between many model configurations (e.g. different predictors or predictor sets, transformations, types of statistical models) - lets return to this when we consider p-hacking
You might have noticed that many of the above factors contribute to the standard error of a parameter estimate/model coefficient from the GLM
Small N
Big p
Small \(R^2\) (weak effects)
Correlated predictors
The standard error increases as model overfitting increases due to these factors
Question: Explain the link between model variance/overfitting, standard errors, and sampling distributions?
Show Answer
All parameter estimates have a sampling distribution. This is the distribution of estimates that you would get if you repeatedly fit the same model to new samples.When a model is overfit, that means that aspects of the model (its parameter estimates, its predictions) will vary greatly from sample to sample. This is represented by a large standard error (the SD of the sampling distribution) for the model's parameter estimates. It also means that the predictions you will makein new data will be very different depending on the sample that was used to estimate the parameters.
Question: Describe problem of p-hacking with respect to overfitting?
Show Answer
When you p-hack, you are overfitting the training set (your sample). You try outmany, many different model configurations and choose the one you like best ratherthan what works well in new data. This model likely capitalizes on noise in yoursample. It won't fit well in another sample. In other words, your conclusions are not linked to the true DGP and would be different if you used a different sample.In a different vein, your significance test is wrong. The SE does not reflect the model variance that resulted from testing many different configurations b/c your final model didn't "know" about the other models. Statistically invalid conclusion!
Parameter estimates from an overfit model are specific to the sample within which they were trained and are not true for other samples or the population as a whole
Parameter estimates from overfit models have big (TRUE) SE and so they may be VERY different in other samples
Though if the overfitting is due to fitting many models, it won’t be reflected in the SE from any one model because each model doesn’t know the other models exist! p-hacking!!
With traditional (one-sample) statistics, this can lead us to incorrect conclusions about the effect of predictors associated with these parameter estimates (bad for explanatory goals!).
If the parameter estimates are very different sample to sample (and different from the true population parameters), this means the model will predict poorly in new samples (bad for prediction goals!). We fix this by using resampling to evaluate model performance.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2023. An Introduction to Statistical Learning: With Applications in R. 2nd ed. Springer Texts in Statistics. New York: Springer-Verlag.
Yarkoni, Tal, and Jacob Westfall. 2017. “Choosing Prediction Over Explanation in Psychology: Lessons From Machine Learning.”Perspectives on Psychological Science 12 (6): 1100–1122.